Launched this week

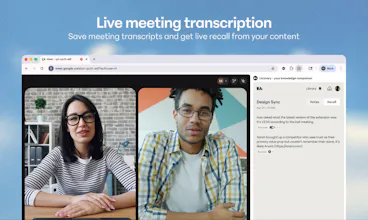
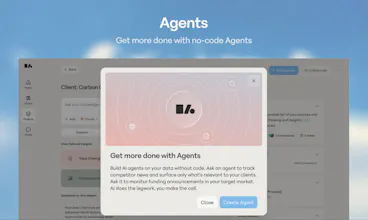
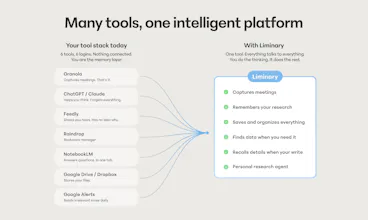
Liminary turns everything you’ve saved into working memory for AI. Unlike chatbots, meeting tools, or project-based notebooks, it gives your knowledge one shared memory across writing, meetings, and research. It surfaces relevant context automatically as you work, helping expert knowledge workers reuse their best thinking, avoid starting from scratch, and produce source-grounded work with traceable citations.






Free Options
Launch Team / Built With



Mailwarm
Congratulations!
The real value, to me, is not saving knowledge, but making past thinking reusable at the exact moment it matters.
how do you handle memory hygiene over time, especially when old context becomes outdated or no longer reflects the user’s current thinking?
Liminary
Thanks@thamibenjelloun! And yeah you nailed it. Storage for the sake of saving isn't the point. Finding at the right moment and finding the most relevant thinking is the problem we're trying to solve.
We're carrying over a lot of lessons from working on retrieval at Dropbox. Couple big ones we leverage are that recency is a strong signal, but so is access. When you look for something new that's related to an older note, that tells the system the older note is still alive in your thinking, even if you haven't touched it in months. It earns its way back up.
Also as users curate collections we treat those as living, not append-only, so pruning and regrouping is part of the workflow, not a chore bolted on top. Updates supersede instead of piling up, so when you rewrite a note the new version is what gets retrieved and the old framing doesn't keep haunting you. And you stay in the loop. When Liminary surfaces something, you can dismiss it, edit it, or mark it as outdated, and that feedback shapes what shows up next time.
Honestly hygiene is a hard, ongoing problem, and I'd rather make curation lightweight and continuous than pretend the system can fully self-clean.
In real workflows, do people actually maintain structured "knowledge sets." or does it become messy over time?
Liminary
@cody_spencer In reality, it gets messy. It's just how knowledge work typically happens -nobody has time to file things perfectly in the moment.
What we found talking to consultants is that the maintenance burden itself is what kills most knowledge systems. People start with good intentions and a clean folder structure, then three weeks into a busy engagement it's already out of date and they've stopped trusting it.
Liminary is built around that reality. It reduces the overhead of maintaining a knowledge system over time. You save things as you go, and the system does the organizational work in the background. The knowledge set emerges from your actual workflow rather than requiring a separate one to keep it alive.
The 'ground in saved knowledge' framing solves the part everyone hand-waves. I lose 20 minutes a day re-pasting the same context blocks into different chats. Curious how you avoid the typical RAG failure mode where the model picks the longest snippet over the most relevant one. Reranker step or pure embedding retrieval?
Liminary
@whateverneveranywhere Good question. Short version: neither pure embeddings nor a reranker on top of them. The architecture is built to avoid that failure mode upstream rather than patch it downstream.
Two pieces. At ingest we run an extraction process that builds structured understanding of each source, so retrieval isn't operating on raw chunks. At query time, the answering layer is built to consume that structured understanding, not a top-k pile of snippets ranked against the question.
So you never get the "longest snippet wins" failure because nothing in the system is choosing between similarly-embedded snippets and hoping the right one floats up.
Interesting idea, but I keep thinking about whether "always-on context" actually improves thinking or just adds more noise.
Liminary
@easton_grant Always-on implies a constant feed, which would absolutely add noise. What we're building at Liminary is closer to ambient context.
Our goal is to minimize the cognitive overhead - focused, high-quality context when you need it, not a constant stream to distract you. The quality of the context that is surfaced is where Liminary can prove its value.
Liminary
@easton_grant Always-on is definitely a challenge, and we spent a lot of time balancing the utility vs distraction question. Like Kevin said, the goal isn't to be on for the sake of being on, but to be available in-context when you actually need it.
A good example: we built controls so users decide when to run fact-check or gap detection while writing, instead of firing those pre-emptively. Surfacing them uninvited can break flow, even when the insight is useful.
Still something we're learning and want to tune per user, because everyone's threshold for "helpful nudge" vs "get out of my way" is different.
Liminary
@easton_grant Hi Easton, It's a big design challenge to present more information in a way that's not distracting, yet there when you need it. When our goal is providing value instead of asking for engagement, we're at an advantage. We're constantly simplifying language, creating clear information hierarchies and tweaking our model's instructions so the user can choose what's helpful to them.
Feels like the hardest part here is not retrieval, but knowing what not to bring into the moment.
Liminary
@dylan_hayes2 Yes, you've identified what we think is actually the harder design problem. Retrieval is largely solved. Knowing what's relevant to the moment - and what isn't - is where the real work is.
It connects back to something Sarah said early on: people don't always know how to describe what they want, but it's almost always inferable from the context they're operating in. That's the principle Liminary is built around.
And when it doesn't have a confident answer, it says so rather than filling the gap with something plausible-sounding.
How does it handle conflicting versions of the same idea across different notes or time periods?
Liminary
@caleb_hunter_guahip It's a genuinely hard technical problem, and one the team has thought carefully about. When you save sources into Liminary, they don't just sit in a file store waiting to be retrieved. The system runs an extraction process immediately, building an understanding of the content that includes the relationships between sources - where things corroborate each other, and where they contradict.
So if you saved a client interview from six months ago and a more recent one where the same person has changed their view, Liminary doesn't flatten those into a single answer and present whichever ranks highest. It surfaces both, with enough context for you to see where the tension sits.
Congratulations on the launch! I've been a beta user for months!
What I like about Liminary is that it is not just a place to save links and forget them.
I use it throughout the day to save articles, emails, Substacks, and other sources I want to come back to. I can pull out notes as I go, organize things by theme, and then revisit them later in a way that actually helps me see connections.
The weekly summary is one of my favorite features. It helps me spot patterns, trends, and even contradictions I might have missed when I was reading things one by one.
Plus--the @Liminary team is amazing, super responsive and helpful!
Liminary
@michelle_dawson_silbernagel Thank you for sharing how you use Liminary! Wonderful to hear how it fits into your workflow. I’m especially glad the weekly summary is helping you spot those trends and contradictions - I agree this is where the insights can be surprising!
Liminary
@michelle_dawson_silbernagel Michelle!! You've been with us through versions of this product that barely worked, and the fact that you're here saying this on launch day means more than I can put into a PH comment. Thank you!