Launched this week

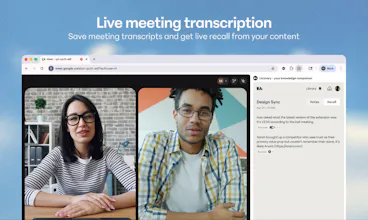
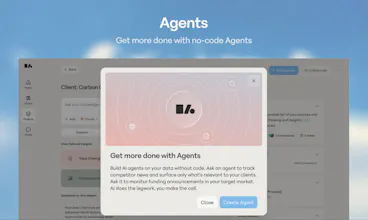
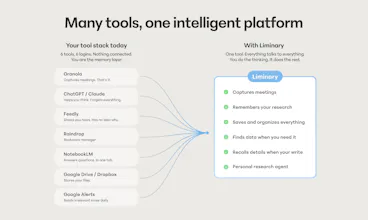
Liminary turns everything you’ve saved into working memory for AI. Unlike chatbots, meeting tools, or project-based notebooks, it gives your knowledge one shared memory across writing, meetings, and research. It surfaces relevant context automatically as you work, helping expert knowledge workers reuse their best thinking, avoid starting from scratch, and produce source-grounded work with traceable citations.






Free Options
Launch Team / Built With



Liminary
@lakshminath_dondeti Great question, especially given how recent Dreams is. The short version: they live at different layers and solve different problems.
Dreams is infrastructure for developers building agents on Claude. It's a scheduled process that reviews an agent's past sessions, extracts patterns, and curates memory so the agent gets better at its task over time. The user is the agent, in a sense.
Liminary is the user-facing analogue, but for you. The system continuously builds a memory of how you actually work, what you save, revisit, ignore, connect, ask about, and uses that to shape what gets surfaced when you're thinking through something. That memory isn't tied to one agent either, it's shared context that every agent inside Liminary draws on, so personalization compounds across the whole system. The user is you, not an agent serving you.
And you're right that this layer should be LLM-agnostic. We're built that way intentionally. Liminary uses multiple model providers under the hood (Claude, GPT, Gemini, Nova, other open source models) for different tasks, but the memory and retrieval layer is ours and sits independent of any one of them. Concretely, if you want to chat with ChatGPT, Claude, or Gemini about your content, you can. All three model families are available to chat with inside the product. The thesis is that your knowledge layer shouldn't be locked to whichever model company you happen to use today, because the model you use will change, and your knowledge should compound across all of them.
If I type something into ChatGPT, will your service see or remember it? Or does it only work with documents from my computer?
Liminary
Hi @natalia_iankovych Liminary doesn't watch your ChatGPT activity in the background, nothing gets captured unless you choose to save it. So you stay in full control of what goes in.
That said, ChatGPT chats are very much something you can save via our browser extension. Anything you'd want to keep, a useful answer, a back-and-forth that helped you think something through, a research thread, you can capture it into Liminary so it's there later when you need it.
And it's not just ChatGPT or local files. You can save web pages while browsing, upload from your computer, pull in from Google Drive, and record Google Meet meetings. The idea is to capture the things you actually use to think and work, wherever they live, in one place that surfaces them back to you when relevant. Additionally if you want to chat with ChatGPT, Claude, or Gemini about your content you can. Liminary has all three model families available to chat with in product.
ProdShort
Can Liminary surface contradictions between old notes and new research?
Liminary
@bengeekly Yes, this is something we built for specifically. If an older note and a newer source disagree, Liminary surfaces both rather than picking a winner, with citations back to each so you can see exactly where the contradiction is. Especially useful for research-heavy work where what was true six months ago might not be now.
Finally something that actually works to bring together the context mess I've created across my digital universe!
Liminary
@matthew_barclay Thank you Matthew, this means a lot. The "context mess" framing really resonates, it's the exact problem that got me to start building this. Hope Liminary holds up to that promise as you actually use it, and please tell me when it doesn't.
The proactive recall idea feels genuinely useful because most knowledge tools still depend on users remembering what to search for, so surfacing relevant context automatically feels genuinely useful. How Liminary handles situations where saved sources conflict with each other. Does it show both perspectives or mainly prioritize the one it considers most relevant?
Station
The interesting part here isn’t “AI memory” itself, it’s grounding everything in sources you actually chose to save.
Most AI tools still feel like they’re guessing your context half the time. Congrats on the launch guys!
Liminary
@campritchard Cam, you summarized this better than most of our own marketing copy honestly. "Guessing your context half the time" is exactly the failure mode we're trying to design out. Thanks for the support, and congrats on Station!