
Sales teams have been stuck with stale databases for 15 years. Jesse changes everything.. the first internet-wide search engine built for sales & marketing. Ask in plain English: "Find newly opened soccer facilities in the Midwest needing turf solutions." Jesse scans the live web and finds the right buyers in the market today. We are an anti database company, we don’t scrape and store stale databases and sell them at premium. Every lead is found fresh from the live internet and delivered.







Forum Threads


What are the BEST and WORST lead gen tools you have tried?
While building Jesse, I talked with a ton of founders, builders and asked about their experience with the best and worst lead gen tools they have used.
I am curious to know the opinion of this group on this matter.
Some common ones that many use today are:
> Apollo
> Clay
> Lusha
> Zoominfo
Feel free to name and mention any other tools that you have come across.
This is the single biggest GTM mistake
Not building lookalike list.
All of us must be having some customers. Some customers came inbound, few via referrals, few via word of mouth- it does not matter.
What matters is that these customers are able to solve their pains with your product.
Hence, once they are your customers- you should be "finding more of these".
This is by far the most underrated GTM hack I have come across.
There are few lookalike tools you can try- Ocean, Jesse (my product).
While using these tools, you should be able to find out why certain new customers were surfaced- what were the logic behind these new suggestions, and then run a focussed outbound/ABM campaign on those list.
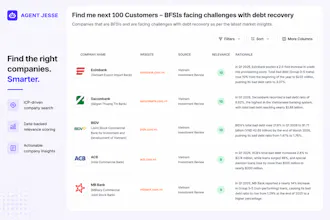
A Guide to Finding Your Next 100 Customers
I ve spent years working on B2B customer acquisition for products moving from early traction to real scale. We tested every channel, built lightweight systems for volume outreach and partnerships, ran hundreds of experiments, and eventually created repeatable processes that a small team could run without constant firefighting.
Distribution is the #1 bottleneck you ll hit. Features get copied. Messaging gets borrowed. What actually compounds is a clear system for identifying the right accounts, testing quickly, and turning early signals into consistent pipeline.
By the end of this you ll know:
- What each major acquisition channel actually buys you (and why most teams misuse them)
This would solve so many problems in prospecting! I normally have to go over multiple surfaces (LinkedIn / X / funding announcements) to find my target customer! What data sources do you use?
@prasoon_shukla2
That cross-surface hunt is exactly the manual work Jesse is built to collapse. Instead of one fixed list, it reads the open web at query time across the surfaces you named, public profiles, social, news and funding coverage, company sites, and synthesizes them into a single ranked result with the reasoning attached.
On top of that we layer a dedicated contact enrichment step for the email and outreach details.
In short: It reads the live public web fresh on every search, instead of pulling from one fixed database. That is the whole point, the cross-surface digging you do by hand now happens in a single search.
Jesse
@prasoon_shukla2 Essentially, anything and everything on the open internet (including forums like X, LinkedIn) are accessed by Jesse.
Voquill
The live web approach is a refreshing take. How often does it refresh or validate lead signals? Congrats!
Hi @henry_habib thanks for the support. It refreshes every time you are creating a new list. Every time you are creating a new list, you provide the right prompt to the agent, and the agent goes to the internet to find out those leads live for you. That means whatever is the new correct information available on those sources, it gets updated. We have a few trusted and verified sources, likes of LinkedIn and other much more active and verified portals. We give a weighted average to these different portals according to their verification status to always give you the most accurate information at all times.
Hopefully this answers the question.
@henry_habib
Thanks.
It refreshes on every new list, the agent goes out to the live web in that moment, so you get whatever is currently accurate on the sources. We weight trusted, verified portals like LinkedIn by how reliable each one is, to keep results as accurate as possible.
Searching the live internet instead of pulling from static lists is a big deal for anyone doing outbound. How fresh is the data — are we talking real-time crawls or is there some caching involved?
@doganakbulut
Thanks.
We do not cache nor use any static list.
Every search reads live web sources the moment you run it, so freshness equals whatever is public right then.
It is live search at query time and not a stored snapshot.
If you run it again tomorrow and it researches from scratch.
The stale-list problem is even worse down-market, Sudipta. I prospect local businesses (insurance agents, salons, clinics) and Apollo/Clay basically don't have them, or the data is years out of date. A live, plain-English search is exactly the gap there. Genuine question: how does it do on small local SMBs vs the enterprise/BFSI examples? That long tail is where every list tool falls apart. Congrats on the launch.
@david_marko
Thanks David.
Great question.
The long tail is exactly where live search should beat static lists.
Jesse does better down-market than Apollo or Clay precisely because it is not a B2B contact database. For a salon, a local agent, a clinic, it reads the live web, Google Business and Maps, local directories, the shop's own site, reviews, which is where those businesses actually live and where contact databases are thin or years stale.
So on finding the business and its public contact info, the long tail is a strength for us, not a weakness.
Two honest limits:
It still needs some public footprint, a listing, a site, a profile. A truly invisible shop will not surface and we will not invent it.
And contact depth is thinner down-market for everyone, us included, you will most definitely get the listed business email and phone, but a verified personal email for the owner becomes progressively harder.
This is exactly where we want to win. Send me a slice of the SMBs you chase and I will run a real batch and show you what comes back.
Hey Product Hunt, Ritesh here, one of the makers.
We built Agent Jesse around one uncomfortable number: B2B data decays about 2% a month, so any static lead list is partly wrong the day you export it.
So Jesse doesn't query a snapshot. It retrieves against the live web at query time, ships every row with the source URLs it came from, and runs a self correcting loop that keeps re-sourcing until it hits your target.
As of this week it also goes where you work: an API key drops it into n8n, and an MCP server connects it to Claude, ChatGPT, or Cursor, so you can just ask for leads in plain English.
We are still actively shaping what comes next, so I would love to hear: where does your current lead data let you down most?
Happy to go deep on how the retrieval or verification works.
Nektar
Cool product. Do you integrate with a CRM directly and can find leads based on winning deals signals/painpoints/characteristics?
@abhijeet_vijayvergiya
Thanks. Two parts to this.
On winning-deal signals: yes, this is core. Hand Jesse a set of your closed-won accounts and it runs a lookalike search, finding companies that match the characteristics of what already wins for you, and you can fold pain points and traits straight into the criteria. So "more like my best deals" is exactly a usecase we solve for.
On CRM: not a native sync yet. Today you get leads in via CSV, or through our new n8n integration using n8n's HubSpot and Salesforce nodes. A direct CRM connection, pushing leads out and pulling winning-deal signals in automatically, is what we are building next.
Which CRM are you on? That helps us prioritize the native integration.
Most of our buyers are pretty active online, so this should work well. But how Jesse handles signal quality when the web footprint is thin like a company that exists but rarely posts. Does it still rank them, or filter them out?
@amanpreet_zop
Good edge to probe.
Jesse ranks rather than hard filters, so a real but quiet company still shows up as long as there is enough public signal to confirm the match.
A thin footprint usually just means a lower score and a shorter rationale, not exclusion, and every result carries the evidence we actually found plus a source, so you can judge the borderline ones yourself instead of us dropping them silently.
The honest boundary:
If a company has effectively no public trace, there is nothing to ground on, so it will not surface, and we will not pad the list with guesses to hide that.
If they are quiet online, no problem. If there is nothing online at all, that is the only case we cannot find them.