Launching today

Sales teams have been stuck with stale databases for 15 years. Jesse changes everything.. the first internet-wide search engine built for sales & marketing. Ask in plain English: "Find newly opened soccer facilities in the Midwest needing turf solutions." Jesse scans the live web and finds the right buyers in the market today. We are an anti database company, we don’t scrape and store stale databases and sell them at premium. Every lead is found fresh from the live internet and delivered.

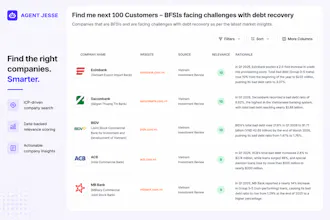






Most of our buyers are pretty active online, so this should work well. But how Jesse handles signal quality when the web footprint is thin like a company that exists but rarely posts. Does it still rank them, or filter them out?
@amanpreet_zop
Good edge to probe.
Jesse ranks rather than hard filters, so a real but quiet company still shows up as long as there is enough public signal to confirm the match.
A thin footprint usually just means a lower score and a shorter rationale, not exclusion, and every result carries the evidence we actually found plus a source, so you can judge the borderline ones yourself instead of us dropping them silently.
The honest boundary:
If a company has effectively no public trace, there is nothing to ground on, so it will not surface, and we will not pad the list with guesses to hide that.
If they are quiet online, no problem. If there is nothing online at all, that is the only case we cannot find them.
Mailwarm
How do you verify the leads are actually newly opened and not just old pages getting reindexed?
@thamibenjelloun
Thanks.
Sharp question.
We anchor recency on the dated signals in the source itself, a funding date, a role start date, an article's publish date, not on when a page was crawled.
A reindexed old page keeps its original dates, so a recrawl does not make it look fresh.
The honest limit is undated or evergreen pages, where age cannot be read from the content. We do not stamp those new, they land with a low relevance score and the source attached, so they rank near the bottom and you can see the signal is weak rather than us passing it off as a confident fresh lead.
A structured recency check, filtering to genuinely changed in the last N days, is what we are building next.
Hey Product Hunt, Ritesh here, one of the makers.
We built Agent Jesse around one uncomfortable number: B2B data decays about 2% a month, so any static lead list is partly wrong the day you export it.
So Jesse doesn't query a snapshot. It retrieves against the live web at query time, ships every row with the source URLs it came from, and runs a self correcting loop that keeps re-sourcing until it hits your target.
As of this week it also goes where you work: an API key drops it into n8n, and an MCP server connects it to Claude, ChatGPT, or Cursor, so you can just ask for leads in plain English.
We are still actively shaping what comes next, so I would love to hear: where does your current lead data let you down most?
Happy to go deep on how the retrieval or verification works.
I have seen my fair share of stale leads and contacts so great job for focusing on an unsolved problem. What markets do you focus on? Are there ones that are stronger or weaker? Interested in learning more. Congrats on the launch.
@yumi_joh
We are not locked to one vertical. Because Jesse reads the live web per search, the real dividing line is web footprint, not industry or geography.
It is strongest wherever your targets leave a public trail, B2B tech and SaaS, funded startups, anything with news, funding, hiring, or active profiles, all easy to find and rank with a solid rationale. The tougher cases are low web-footprint targets such as very tiny local businesses, stealth-mode companies, low-digital-presence industries or regions, where signal is sparse so results come back fewer and lower confidence.
Widening that thinner end is what we are working on now.
Happy to go deeper. What market are you selling into?
I will tell you honestly how strong a fit it is.
@ritesh2503 thanks for the complete response and great to know that there is no boundaries on geography. My ICP will leave a trail of information so with this information, I'm excited to give Jesse a spin.
@yumi_joh Thanks for the support. Yes we do work better for markets that is unexplored / not easy to find on traditional databases like Apollo and Zoominfo. These will be the non-digital markets from traditional industries like:
1. Manufacturing
2. CPG, D2C, ecommerce
3. Finance
etc
We also work better for geographies where the coverage is poor such as APAC, Middle east etc.
Since these are hardest to curate in traditional databases and were only accessible by having a person comb through google searches and build the list, we made them a staple usecase for Jesse.
That being said, it gives equally good results for other markets that you might be exploring.
@sarthak_shrivastava2 Gotchu. Will give it a go and see how prospecting looks from Europe. Thanks
@amitkumar0331
Thanks.
Yes, through MCP, with Claude Desktop, Claude Code, Cursor, and the API, connected via your Jesse API key.
The MCP access is in request-only beta right now, not open yet, and goes fully public in a couple of days.
DM me and I will get you in early.
One caveat: the claude.ai web connector panel needs OAuth rather than a pasted key, so that exact surface is not live yet. It shall be live in a couple of days as well.
Scoutflo
This is such a cool product! Clay was super hard for me to use.
Is there a free trial to get started?
@kalpesh_bhalekar1 Thanks for the support. Yes, we have provided a free trial to all our customers to try out Jesse. Even then, after we start with base plans at just $5/month, they can go up to $100 according to your requirements and needs.
This is interesting. Do you cache results at all, or does every search query the live web fresh?
@dhiraj_patel5
Thanks Dhiraj.
Every search hits the live web fresh, no cache serves an old answer to a new query, so re-running a prompt researches again rather than replaying.
We do save a completed search's results so you can reopen, paginate, and export them, but that is storing a finished run, not caching the web.