Launched this week

Weavable
Give every AI agent persistent work context
373 followers
Give every AI agent persistent work context
373 followers
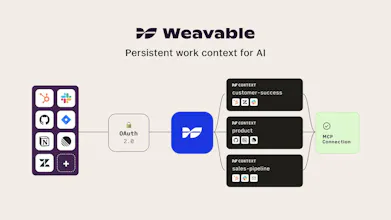
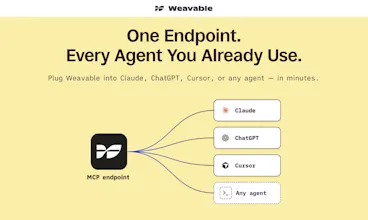
Weavable gives AI agents persistent, live work context from the tools your business already runs on. Through a single MCP endpoint, it turns scattered updates, relationships, and system changes into a usable context layer so agents can reason more accurately without constantly re-ingesting data. The result is lower token usage, better outputs, and more reliable agent behavior across real business workflows.





Persistent context across agents is the exact problem most multi-agent systems hit. Workspace isolation makes context sharing safer — without it, cross-tenant leakage is a real risk. How are you handling tenant boundaries?
Weavable
@pengspirit666 Excellent question, and something we see quite often when working with larger companies.
The control itself is defined when you curate a context. That's where you set which data scopes are in, which are out, and who the context is available to. Cross-tenant boundaries can be enforced both there and at the OAuth layer, depending on which connections each side of the boundary should be able to reach. Additionally, every query against a context is logged too: which agent, which user, which signals were retrieved so the entire flow becomes auditable.
@abesh_thakur The "control at curation" framing tracks — same shape lands in the
fulfillment-MCP corner of the protocol. Workspace-scoped routing means the
operator decides at workspace creation which adapters are reachable, and
the agent inherits that scope rather than negotiating its own permissions.
The audit-log piece is what most implementations defer. Logging which
agent + which user + which signals retrieved is what turns "MCP is
reachable" into "MCP is auditable" — different product entirely.
Open question: do you log the rejected reads too (the context-not-curated
case), or only successful retrievals? Rejected reads are the part that
catches scope drift early — an agent repeatedly trying to read outside
the curation envelope is usually a signal you want surfacing before the
next quarterly access review, not after.
Weavable
@pengspirit666 thanks for the great question and support!
Really cool! How do you think about trust boundaries when agents have persistent cross-system awareness?
Weavable
@brucewalker_ Great question! Since the apps connect to Weavable using OAuth, the system can only access and process data that a specific user is already permitted to see across contexts within the parent applications.
On the other hand, if you want to use a global admin to share everything within a given set of tools across the organization, you can do so without having to reconfigure the entire system.
I think this approach makes governance across the AI stack much more manageable, and allows the system to scale.
The lack of long-term memory is usually what kills agent utility in SaaS. How does Weavable handle context pruning so the agent doesn't get 'confused' by old or conflicting data?
Weavable
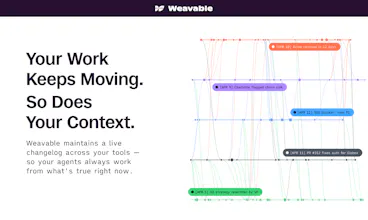
@rivra_dev Good question! Pruning isn't quite the right primitive here. Throwing context away means losing the ability to reason about change over time, which is half of why the activity graph exists.
Instead, everything in the graph is timestamped and ordered. When an agent queries a context, it gets the current view by default: the latest state of each entity with the connections that matter now. Older states stay in the graph but sit behind the current view, available when the agent needs to reason about how something changed.
Conflicts work the same way. If two sources disagree, both are stored with their provenance, and the current view surfaces the one ranked authoritative for that signal type. So the agent isn't sifting through old or contradictory data. The graph has already resolved it.
Atlas Navigation
Interesting approach. We use claude code heavily for our startup and the biggest friction is re-explaining context every session. Curious how this handles context that changes fast, like when you're shipping multiple features in a day and the codebase is shifting under you.
Weavable
@tjclayton great point, but this is also where building a changelog based graph really helps - in fact, being able to capture the fast moving codebase for example is essential because static snapshots, or multiple queries (like you hinted at in your case) isn't going to get you reliably there or at a much greater cost.
Atlas Navigation
@abesh_thakur That makes sense. The changelog-based graph is a smarter approach than just dumping the whole repo into context every time. Going to look into this more closely.
Weavable
@tjclayton Just DM me directly if you need anything at all!
Why does token usage decrease? Usually, the more memory there is, the more tokens are needed. How did you design this mechanism?
Weavable
@natalia_iankovych Great question! Here's how we think about it overall - the intuition that "more memory = more tokens" is correct for raw storage, but that's not what's happening here.
The cost in typical setups isn't just storing data, it's preparing it at query time. When an agent pulls raw records through direct MCP calls, the model has to ingest everything, figure out what's related, sort by recency, and reason over the full dump - even if only a small slice of it is relevant to the actual question.
Weavable pre-processes that work. The graph already tracks relationships between entities and knows what changed when, so by the time a query comes in, we're serving a pre-assembled, change-aware payload rather than a raw data firehose. The model reasons over the signal it actually needs, not everything that could be relevant.
The 90% isn't a theoretical number - it's what we consistently see on real workflows like pre-meeting briefs, renewal risk analysis, and pipeline summaries when you compare against the same workflow built on raw MCP calls.
Weavable
Jumping in as the other maker.
Here’s the bet underneath everything we built: work isn’t just documents or records. It’s activity. The things people and agents do over time. A renewal slips because three signals lined up across CRM, support, and Slack that nobody connected. A deal closes because of a conversation in a thread, not a field.
The record is the residue. The work is what moved.
Most AI context tools either flatten all of that into a snapshot, or stitch together a handful of MCPs that make endless calls against flat records, pollute the context window, and still don’t know what changed or why. We thought both were wrong.
So we built Weavable on a deterministic engine that tracks how information changes, builds a changelog of every meaningful update, and stitches it into an activity graph. That graph is what your agent queries through the MCP endpoint. Not a summary, not a vector blob. A structured, time-aware picture of what’s actually happening. And because your agent can query for the specific signals it needs, it doesn’t ingest an entire workspace to find them. Less context window, less cost, sharper answers.
Would love to hear from anyone who’s tried to solve this differently. We think the activity-graph approach is the right primitive, but we’re early enough that we want to be wrong out loud if we are.
The product looks like a genuinely useful tool, but it was shared to me by somebody on LinkedIn selling upvotes as a service pretending that it is their product.
Weavable
@lewisrogers Thanks for flagging this Lewis! To be clear, this was not us, but we really appreciate the good faith outreach to bring it up here rather than just ignoring it. If you can DM me the LinkedIn profile, we can follow up with PH so they can act on it.
Weavable
@lewisrogers Took a quick look at ReadySetLaunch as well - congrats on building something that looks genuinely useful too!