Launched this week

Weavable
Give every AI agent persistent work context
375 followers
Give every AI agent persistent work context
375 followers
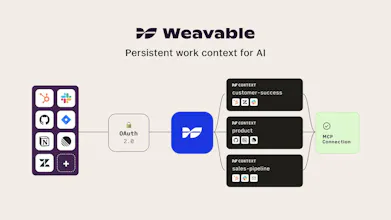
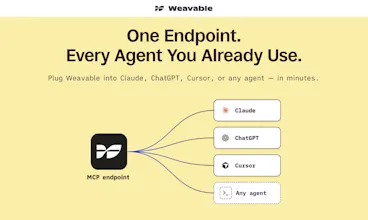
Weavable gives AI agents persistent, live work context from the tools your business already runs on. Through a single MCP endpoint, it turns scattered updates, relationships, and system changes into a usable context layer so agents can reason more accurately without constantly re-ingesting data. The result is lower token usage, better outputs, and more reliable agent behavior across real business workflows.





The shift from static RAG snapshots to a continuous updating changelog for agent context is an interesting move to solve the 'stale data' problem. How does Weavable handle conflict resolution when multiple tools (like HubSpot and Slack) provide contradictory updates to the same shared context layer? I'm also curious if the single MCP endpoint architecture allows for custom logic to prioritize specific 'event types' over others to further protect the agent's context window.
Less flashy than most things in this space but probably more important. Agents keep losing context or reprocessing the same information because there's no real memory layer underneath them. The thing I kept wondering about though is how hard it’ll be to keep that memory clean and trustworthy at scale. If you’re pulling from Slack, Jira, GitHub, HubSpot, etc. in real time, one bad or outdated source could quietly affect decisions before anyone even notices.
Anyways, it feels focused on a real bottleneck instead of just adding more autonomy for the sake of it, and I really like that. If agents are actually going to become useful inside companies, they probably need some kind of reliable long-term memory layer like this.
Lancepilot
Weavable
@odeth_negapatan1 Great question - it's on point.
Every app is connected to a user's context through OAuth, which means for teams using shared contexts, the underlying permission model is never changed - whatever they were able to see originally is what they can see using Weavable, nothing more, nothing less. This is a critical area of work for all things agentic, so clear UX and scoped context creation has been a pretty major focus for us as we build this.
fforward.ai
Congrats on the launch guys!
A lot of AI workflow tools solve “access to data,” but not necessarily “understanding evolving organizational context.”
Curious how you think about context drift over time. For example, if priorities, ownership, or relationships between systems change gradually across Slack, Jira, HubSpot, etc., how does Weavable ensure agents are reasoning from the current operational reality rather than stale inferred relationships?
Also interested in whether you see this becoming more of a “system of context” layer that other agent frameworks standardize around long term.
Weavable
@maxcameron Excellent question Max, and thanks for the support!
There are a few ways to handle what you mentioned. We think of solving this through a combination of
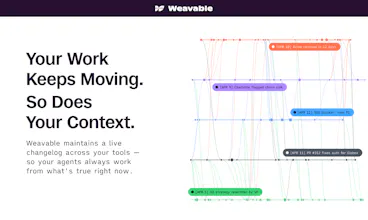
a) a changelog-based graph that keeps its context relational and up to date and
b) being able to reason across these scoped contexts - for example, understanding the real state of a deal based on not just the last meeting notes left there, but continuing conversations on Slack threads internally
These directionally already go a long way in determining the state of affairs, and we eventually have to get to a, as you called it, a system of context. You do raise a great point about standardization overall - lots to think through!
Personally, token usage and repeated context loading have been one of the biggest pain points for me while working with AI workflows, so this direction immediately stood out.
I really like the idea of persistent work context and reducing unnecessary token overhead while still improving reasoning quality across workflows.
One thing I’m curious about is how retrieval quality is maintained for older conversations or long-running contexts. If context is being compressed or optimized for efficiency, how do you ensure important historical information isn’t lost over time when an agent needs to access much older data again?
Nice! I loved the activity graph/changelog approach since I was building an escrow platform where the agents need to understand the startup milestones, investor relationships, and payment histories simultaneously. Flooding the context with raw Firestone data was exactly the failure I ran into.
Weavable's approach of maintaining a live graph and querying only what's needed is the right mental model I wanted.
Weavable
@pranav60 thanks for sharing your story Pranav! Curious - were you able to get a handle on it at the end?
The activity-graph approach makes more sense than static RAG or raw MCP calls — context that reflects what changed is fundamentally more useful than a snapshot. Curious how Weavable handles conflicts when the same entity (like a customer) appears differently across Slack, HubSpot, and Zendesk. Does it reconcile automatically or flag it for review?