I was a beta user, and what impressed me was how quickly they responded to messages and feedback. As a creative who uses tech across my workload I attend a lot of meetings and trainings. I also do a lot of independent work. I have a storehouse of information that is curated and easy to manger. I can delete old information and update it with new info very quickly.
There are great features I didn't even know existed until I explored. For example I went to a class and wanted to turn the information into informative posts. I uploaded in the class material then went to the "create" session and after 5 minutes chatting with the AI had about 6 very indepth and accurate information posts. And this was on a niche, let's say adult, educational class. It is important the information was correct and informative. I know the source, so I know it was.
Also, speaking of it--how flexible. No moralizing, to watering down, no "oh, let me tell the human what it wants." It's a memory bank and partner in making the information you have useful.
Since I'm busy the ability to chat up Liminary and ask it questions that I know I vaguely remember I learned somewhere is huge. An open question like, "Hey, what do I know about drafting a super prompt to do XYZ" makes me much more efficient. For my ND brain, I use it as very flexible backup. I can even build agents that do automatic things like track reader trends and have Liminary update itself on a daily, weekly, or custom schedule. That information automatically becomes part of my knowledge bank, and can be updated at anytime.
Very easy to use. Even sends me weekly recaps of "here is what you learned this week". When I entered the beta I wasn't sure how helpful it would be. I now am an annual member that uses it all the time.












Liminary
Hey Product Hunt 👋 I'm Sarah, founder of Liminary.
I led ML engineering for Dropbox. Semantic search, retrieval, and Dropbox's first generative AI integrations. I built Liminary out of personal frustration: storage is archival. I couldn't save articles, meeting notes, and the useful AI conversations in one place, and then on top of that, I'd never see any of it again. Lost in closed tabs, various note taking apps, emails, and AI chats.
AI tool proliferation made it worse, not better. Every new model meant re-benchmarking, redoing workflows, re-feeding context. As a builder, I believe users should get the best model for the job, not chase whichever one shipped this week.
But there's a deeper problem beneath both of those: every AI tool you use is working from what the model thinks is relevant. Trained on the internet, guessing at your context. Not what you've decided matters. That's the gap.
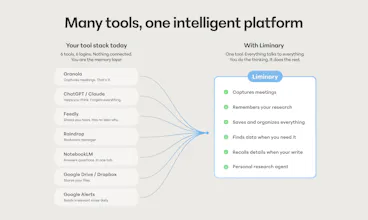
Our team at Liminary is all ex-Dropbox and ex-Google. We built Liminary to close that gap: the memory layer for your AI work. You decide what goes in: files, web pages, YouTube videos, LLM transcripts, Gmail threads. Your AI works from that. Always.
Liminary lives across the surfaces where you work: a browser extension, a writing sidekick in Google Docs, a meetings layer, and a place where everything you save lives and connects.
Three things Liminary does that no other tool can:
Proactive recall. The right knowledge surfaces at the moment of work. You don't search. It finds you.
In-context fact-check and Gap detection. As you write in Google Docs, Liminary validates claims against your own library, finds what’s missing from the research you already did or the information your clients already shared with you. Not the web, not training data.
Meeting recall, live. No bot in the room. When someone says "Project Atlas," your notes already read "Project Atlas with Alice and Bob [source]." Other meeting tools take notes. Liminary connects what's said to everything you already know.
Built for people who bill for their perspective: independent consultants, fractional leaders, VC analysts and strategists. In a world where everyone uses the same models, your edge is what those models are grounded in.
The work looks like this: you keep ambient context on a small set of clients, accounts, companies, or topics you think about repeatedly. You research them. You meet about them. You produce deliverables about them. Liminary connects all three, so the research, the meetings, and the writing all work from the same knowledge.
What's the one piece of context you wish your AI actually remembered?
Early days. Honest feedback welcome: liminary.io
~ Sarah and the Liminary Team
Strong work on the extraction architecture. I'm curious on how you handle data sovereignty for consultants with NDA'd client materials—is processing local, or do you have isolated tenant architectures? Consultants, for example, need strict boundaries between client A's data and client B's data, not just document-level permissions. I believe engagement-level isolation would matter more than document-level permissions here.
Liminary
@sinchana_v We have strict scoping of sources by collection -- Liminary won't use sources from one Collection when working in another, and using one collection per client is a common pattern among our users. It's not strict host-based isolation, if your contracts require specific technical measures, but it will prevent leakage.
Liminary
@sinchana_v +1 to Tom's answer on the product-level scoping, that's how engagement-level isolation shows up in practice for our consultant users.
Adding the infrastructure side since you asked. Processing isn't local, it runs in our cloud, but the architecture is built around isolation and encryption from the ground up. We run on AWS with tenant data scoped per account, end-to-end encryption in transit and at rest, and KMS for key management. So while it's not on-device, the substrate is enterprise-grade rather than shared general-purpose infrastructure.
On your bigger point, engagement-level isolation mattering more than document-level permissions, I think you're right, and that's why we built the unit of organization to be collections rather than tags or folders. Collections are the boundary, and Liminary respects it across retrieval, synthesis, and surfacing. Permissions on individual documents would be much weaker because the retrieval layer would still cross boundaries when answering questions.
Curious, what kind of client work are you running into this with? Some industries push harder on this than others, and I'd love to understand where you're seeing the friction.
@sarah_andrabiI’m not coming from direct client work here, it was more of a design edge case I started thinking about while reading your setup. My thought was that in some consulting or regulated environments, even retrieval crossing engagement boundaries could become a trust/compliance issue, so the collection-level isolation approach stood out to me.
Congrats on the launch. Grounding AI in saved knowledge feels like the right direction, especially for work where the answer depends on private context rather than general internet knowledge.
The hard part I’d be curious about is conflict resolution. Once people save enough snippets, docs, examples, and notes, some of that context will be stale or contradictory. Does Liminary have a way to show which saved source influenced the answer, or to rank “this is current policy” above “this was a random note from six months ago”?
For me, trust in grounded AI comes less from having more context and more from knowing which context won.
Liminary
@jim_jeffers that's a really good question. Every answer Liminary generates is tied back to the specific saved sources it used. Not a generic list of related notes, but the actual sources that influenced what got synthesized, with one click back to the original. So you can always see which context won per se, not just trust that the right one did.
On the ranking question, recency is a strong signal but not the only one. Access patterns matter too. If you've been pulling on an older note recently, the system treats it as still live in your thinking. And updates supersede, so when you rewrite or revise a note, the new version is what gets retrieved. A random older note only outranks current policy if you've kept engaging with the old one and let the new one go stale, which is usually a signal worth surfacing anyway.
The other layer is that Liminary builds a memory of what you're working on right now and your preferences over time, so retrieval gets tailored to you specifically. The same library of sources can produce different answers for different users, because what's most relevant depends on the work you're in the middle of.
We currently don't yet have a way for users to explicitly mark a source as the authoritative version, but that's definitely food for thought for us. Right now it's inferred from signals rather than declared, which works well in practice but isn't as legible as it could be.
Liminary
@jim_jeffers It's a difficult problem for sure. As you suggest, recency and staleness signals help here; not just when you saved a source, but when did you last reference it, and does it include date information in the content itself. The other very useful bit is that Liminary remembers your previous working sessions. So if you've said once that a piece of information is out of date, Liminary can use that in future sessions.
This makes sense. The “I already told the system this was stale” part is especially important, because recency alone can be misleading in real work.
I like the idea of inferred authority, but I’d still want an escape hatch for explicit authority: “this is the canonical policy/source until replaced.” That seems useful for teams where an old-but-current document should beat a fresh-but-casual meeting note.
Liminary
@jim_jeffers yeah, that's a fair point and a real gap. The use case you described, old-but-current beating fresh-but-casual, is exactly where inferred authority gets thin and you'd want a user-declared signal instead. Definitely something we're going to chew on. Thank you for engaging so thoughtfully with our launch!
I've been thinking about this exact problem. I built a persistent memory system for my AI agents — each one maintains its own JSON file tracking known issues, trends, and changelog — and the coordination between agents reading each other's memories was the hardest part to get right.
The "source-grounded with traceable citations" angle is smart. Most AI knowledge tools lose the provenance chain and you end up not trusting the suggestions. Does Liminary handle conflicting information from different sources?
Liminary
@ytubviral Agent coordination with regards to memory is genuinely a fun problem to solve. Years of building search and retrieval at Dropbox taught us a lot about how this breaks down at scale, and we built Liminary's architecture and memory systems with those lessons in mind.
On the conflict question specifically: at ingest, an extraction process builds structured understanding of each source, including where things corroborate and where they contradict. So if you saved a client interview six months ago and a more recent one where the same person changed their view, Liminary doesn't flatten them into a single answer. Both surface, with the tension visible and citations back to each source.
One thing that helps on the coordination side: the memory layer is shared across every agent inside Liminary, not partitioned per agent. So there's one source of truth underneath, not many that need to negotiate.
This feels powerful, but I'm curious how often it pulls "technically relevant" context that's actually not useful in practice.
Liminary
@charlotte_reed1 good question! I’ve been using Liminary for a month in my consulting work and what I’ve noticed is that the more context you give it, the sharper it gets. For example, it recently linked a specific question a client asked in a meeting to a comment from a strategy audit I did weeks ago.
The technical reason it doesn't just pull "keyword matches" is that it uses more than just text similarity. It treats your access patterns and recency as signals too. If you're looking for something new that's related to an older note, the system treats that as a sign that the older note is still "alive" in your thinking. It also lets you dismiss or mark things as outdated, so the retrieval actually learns from what you find useful versus what’s just noise.
Basically, it’s designed to prioritize your current thinking over just anything that looks similar on paper.
Liminary
@charlotte_reed1 +1 to Kevin. The other thing I'd add is more about how we approach the design problem than the technical one. Precision in practice is genuinely hard to measure, there's no clean metric for useful vs technically related, and it's also dependent on each user's individual preferences. So we lean on a couple of things instead.
First, we let you tell the system when something isn't useful, dismiss it, mark it as not relevant, and that feedback shapes what gets surfaced next time. The system learns your standard for "useful" as you use it.
Second, we deliberately surface less rather than more. It's easier to build something that throws every "related" note at you, but that's how you get the noise problem. Restraint is a design choice.
Still imperfect, and we're tuning it constantly. The bar we hold ourselves to is that a surfaced note that doesn't earn its place is worse than no note at all.
I wonder if users end up trusting the surfaced context too much, even when it's slightly off.
Liminary
@hudson_blake That's a fair concern and honestly one we think about a lot. The research we did with consultants actually surfaced something counterintuitive: as AI models get better, hallucinations become harder to spot, not easier. When errors were frequent, people checked everything. Now that output quality is generally higher, the temptation to trust it goes up, but the stakes haven't changed. A single wrong stat in a client deliverable is still a professional liability.
The way we've approached this is to make verification the default, rather than an afterthought. Everything Liminary surfaces is tied back to a source you actually saved. So if something looks slightly off, you're one click away from the original document.
We're not asking you to trust the AI. We're trying to make it fast and easy to check it. The goal is to collapse what our users call the "reconciliation loop" - that painful cycle of generating output, hunting down sources, and verifying every line before it goes anywhere near a client.
Liminary
@hudson_blake +1 to everything Kevin said. The other piece I'd add: Liminary is a content-first platform, not chat-first like most AI tools. That distinction matters a lot here. We don't respond from an LLM's general knowledge, we respond from the content you've already saved. And what you save required your judgment and expertise in the first place.
So everything downstream of that, what gets surfaced, what gets synthesized, what gets cited, is grounded in a corpus you already vetted. The AI isn't introducing new claims for you to trust or distrust. It's pulling from sources you chose, and showing you exactly which one. That's also why citations are a core part of the product, not just a polish item.
Does the system ever surface too much context and slow down decision-making instead of helping it?
Liminary
@jack_sullivan5 It's a real tension. The design challenge is relevance and timing vs volume.
What we're building is closer to a research assistant who speaks up when something is relevant to what you're working on right now. We notice that decision making tends to be faster when context is fully sourced and prioritized from sources you've deliberately saved.
If something comes up that isn't helpful, that's useful signal too - Liminary will learn from your feedback. The goal is a system that gets sharper over time.