

MiniMax M2.7 vs. Claude Opus 4.6

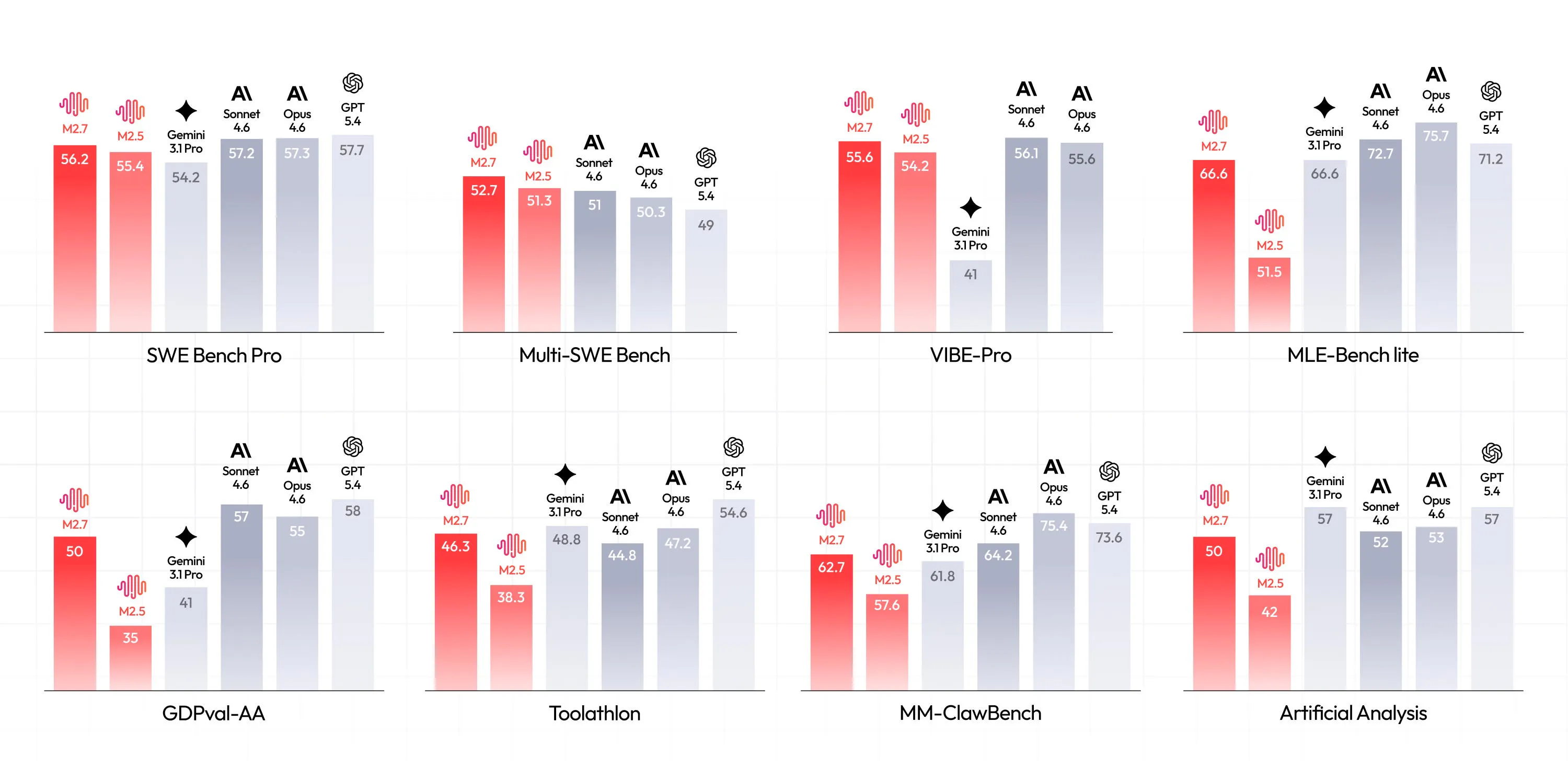
Launched last week, open-source frontier model @MiniMax M2.7 scores 56.2% on SWE Bench Pro, converging towards the best proprietary models like @Claude by Anthropic Opus 4.6.
How do they compare in practice? The @Kilo Code team just ran both models through three coding tasks to see if the benchmark numbers hold up. They created three TypeScript codebases, each model received the same prompt with no hints, and they scored each model independently after all tests were complete.
Key takeaways
Both models found all bugs and security vulnerabilities.
Claude Opus 4.6 produced more thorough fixes and 2x more tests.
MiniMax M2.7 delivered 90% of the quality for 7% of the cost ($0.27 total vs $3.67).
The gap between open-weight and frontier models is shrinking with every release. In another thread on the best AI coding models, [1] some comments rightly suggested finding a balance between performances and prices.
Time to switch?
Replies