
P402.io
Route, verify, and settle paid API calls with clear traces
89 followers
Route, verify, and settle paid API calls with clear traces
89 followers
Most AI apps waste 70% of their budget. Wrong models. No caching. Payment fees that destroy micropayments. P402.shop: Compare 50+ AI APIs (GPT-5.2, Claude Opus 4.5, Gemini 3, more). Find the right model for your use case. See costs explode from 100 to 1M users. Free. P402.io: Accept micropayments without Stripe's $0.30 killing you. 1% flat fee. Built on x402—HTTP's payment standard, finally working. Vibe-coded apps break at scale. Optimized ones don't.



















P402.io
Product Hunt
For model cost optimization, how does P402.io's recommendations compare to just using OpenAI’s or Anthropic’s built‑in cost/perf guidance or tools like OpenRouter’s benchmarks?
P402.io
@curiouskitty Great question
OpenAI/Anthropic's built-in guidance: Inherently limited to their own ecosystem. Anthropic will never tell you "actually, DeepSeek R1 handles this task at 4% of the cost." Their guidance optimizes within their models, not across the market. Same with OpenAI, they'll recommend GPT-5.2 vs GPT-4o, but won't surface that Gemini 2.5 Flash might be 10x cheaper for your specific use case.
OpenRouter: Genuinely good. Their benchmarks are useful for capability comparison. But OpenRouter is a routing/aggregation layer their incentive is throughput, not helping you minimize spend. They show you prices, but don't model what happens to YOUR economics at 100K users vs 1M users. They also don't factor in the payment layer (which is where P402.io comes in).
Where P402.shop is different:
Vendor-agnostic: We have no incentive to push you toward any provider
Scale modeling: Not just "price per token" but "your actual bill at your actual volume"
Task-matching: Recommendations based on use case, not just benchmarks (summarization ≠ reasoning ≠ code gen)
Full-stack view: Model costs are only part of the picture. If you're charging micropayments, Stripe's $0.30 might be bigger than your AI costs
Honestly, use all of them. OpenRouter for capability benchmarks, provider docs for specific features, P402.shop for the cross-provider economics and scale modeling.
We're not trying to replace benchmarks, we're solving the "I'm bleeding money and don't know where" problem.
vibecoder.date
Loving the idea, are you planning to offer MOR capabilities? or stay focused on just payments.
P402.io
My Financé
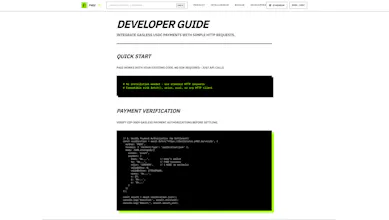
your landing page is really nice! i actually posted internally in slack about how nice it is!
i did notice this unit which is a. very impressive but b. likely a bit off in terms of contrast!
congrats on launching!
P402.io
@catt_marroll thank you for the shoutout on your slack and the heads up. I am pushing a fix for this now, always iterate, really appreciate the feedback!
P402.io
This week marks the transition of P402 from an AI routing concept to a live financial protocol. We have successfully deployed the "Financial Rails" required to make Gemini-powered agents economically autonomous.
Technical Highlights:
1. Backend Overhaul (The Router) We completed a ground-up rewrite of p402.io to support high-frequency Agent-to-Agent (A2A) settlement.
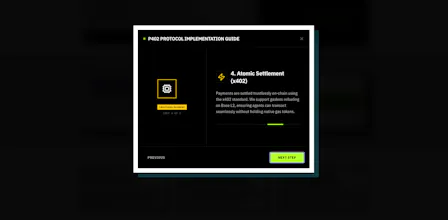
EIP-3009 Implementation: Built a complete exact payment scheme for gasless USDC transfers on Base L2.
Smart Contracts: Deployed P402Settlement.sol and integrated a new Blockchain Service layer (lib/blockchain/client.ts) to replace all simulation stubs with on-chain verification.
Testing: Added a comprehensive integration test suite covering route integrity, API exports, and settlement logic.
2. Architecture Scale: The Edge Network
To support global agent traffic, we secured Cloudflare credits to deploy the P402 Facilitator network.
Topology: 15 global edge regions running Cloudflare Workers.
Performance: Facilitators now handle EIP-3009 signature verification and rate limiting at the edge, ensuring <50ms latency for agent inference requests.
3. The Client: Farcaster Mini-App We updated mini.p402.io to serve as the user-facing control center.
Tech Stack: Next.js + Viem + Farcaster Auth.
Feature: Implemented a custom usePayment hook that handles EIP-712 typed data signing, allowing users to authorize USDC spend directly from their Farcaster identity.
Engineering Metrics:
Volume: 7 major commits across router and mini-app.
Diff: +20,556 lines added / -5,269 removed (Net +15k).
Security: Added Replay Protection, 3-of-5 Multisig Treasury, and Traffic Event logging for audit trails.
Current Status: The system is live on Base Mainnet (Chain ID: 8453). Agents can now query Gemini models via OpenRouter and settle usage in real USDC immediately.
P402.io
This is an A2A protocol? And what models can be connected?