
Oriane
The perception layer for Marketers and their AIs
354 followers
The perception layer for Marketers and their AIs
354 followers
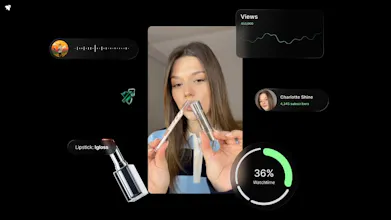
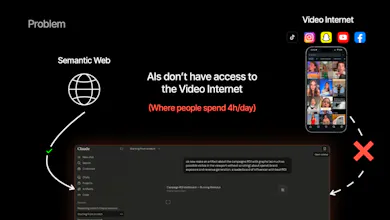
91% of internet bandwidth is led by videos that your AI does NOT watch... Oriane watches millions of social videos a day, and turns what's on screen, in audio and in captions into a structured intelligence layer for teams and their AI apps to find niche creators, spot content trends, identify viral hooks and more!
Interactive



Free Options
Launch Team / Built With



Curious how deep the analysis goes are you just tagging content or actually understanding hooks, pacing, and storytelling patterns?
Oriane
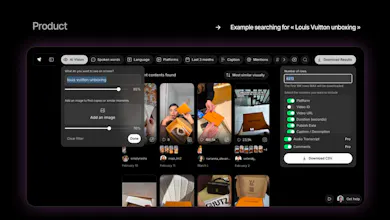
@robert_pim Hey ! We index all dimensions of a video (visual, audio, transcript, caption, comments etc), which then can be turned into different analyses, from a content playbook, hook analysis, shadow reach, and more.
Lots of examples of those on our website explore page :)
Oriane is doing some very interesting work, a few days back when I was using Claude to do some research I realised that it doesn't consider Youtube transcripts as a source; which means that it is leaving out a lot of depth/expertise on the topic in favor of FB/ reddit threads. Curious - on the roadmap, are you thinking about launching an OpenAI/ Anthropic MCP to increase the depth of research for consumers using these platforms?
Oriane
@vidushi_singhal Great observation, and you're naming something we've been
thinking about a lot internally.
You're right that AI assistants are leaving an enormous amount of
expertise on the table by not indexing video. The reason is
simple: nobody has built a clean, structured way to expose video
content to LLMs at retrieval time. Captions and ASR transcripts
exist, but they're noisy and miss the on-screen content entirely.
MCP is exactly where we think this lives. We've been quietly
prototyping an Oriane MCP server that would let Claude, ChatGPT,
or any agent query our index directly during research workflows.
"What did experts actually say about X in the last 90 days of
YouTube" becomes a single tool call.
Not committing to a public date here, but it's on the roadmap
and progressing.
If you'd be open to it, would love to have you in the design
partner cohort when we ship the alpha. The use case you described
(Claude research with video depth) is exactly the persona we want
to test against.
Habéis considerado un plan de pago por videos procesados?
Oriane
@new_user___1252026215fc09078d9d3fb Hi Carlos! We will release our API with an MCP and will have a pay per request model yes!
Oriane
Actualmente tenemos 3 planes disponibles que puedes contratar de forma instantánea, desde el más limitado hasta el más avanzado: Free, Plus y Pro. Puedes encontrar la página de pricing aquí.
Para empresas también ofrecemos planes enterprise, para los cuales es necesario contactarnos directamente.
En este momento, una suscripción te da acceso automático a todos los vídeos en Oriane. A través de la aplicación web no existe ninguna limitación en el número de vídeos procesados dentro de tu acceso. A través del MCP, @julien_rosilio ya respondió!
TrackerJam
The watches millions of video a day claim is wild .Would love to understand the infrastructure behind that.
Oriane
Oriane
@maklyen_may The volume is indeed massive, and it keeps growing.
To make that viable, we need end-to-end control over the infrastructure. Making videos searchable is a challenge in itself, but what you’re pointing at actually sits at the intersection of two major parts of our system: acquisition and processing. Each of them comes with its own complexity. One focused on data retrieval, the other on AI-driven enrichment.
We handle this by clearly separating concerns into fundamentally different stacks and pipelines. That separation lets us better scope how data is ingested, processed, and stored.
From there, consumption becomes a different kind of challenge, but one we can manage internally. That’s what ultimately makes it possible to operate an infrastructure capable of supporting a search experience as broad as Oriane.
the 1000x cost reduction on vectorization is the actual unlock here. built a tiktok audio trend pipeline last year for a content channel and the math on doing it at scale across millions of videos was brutal at the time. brandwatch treating video like text has been the wedge sitting there for years, surprised it took this long for someone to go after it properly
Oriane
@saad_el_gueddari That’s a really sharp take.
You’re absolutely right that the 1000x cost reduction in vectorization is a real unlock. At scale, information processing pipelines designed for human consumption quickly become a bottomless cost sink. Especially once you start dealing with videos and continuous streams.
What we’ve been working on is less about treating data purely through an “AI layer”, and more about making it accessible through the full spectrum of human perception. That doesn’t replace semantic data layers, they are still extremely valuable. But it does break the constraint of purely computational interpretation.
In a way, it shifts the paradigm from “structured data for machines” to “perceptual data" that can be interpreted, filtered, and reasoned over by AI in a more human-aligned way.
@julien_rosilio Watching this from the music side. The luxury wedge makes sense
as a beachhead, but the perception layer applies to everything.
We have the same "captions don't capture the content" problem,
just with audio fingerprinting, sample tracking, and unauthorized
derivative use.
Question for the team: if you were going to expand the perception
layer beyond brand listening, which adjacency would you pick
first? Music IP detection? Sports broadcast monitoring? Live
event surveillance? Curious how you're thinking about the second
beachhead.
Oriane
@abhiranjan_mehta music is the adjacency I get asked about most. Honest:
luxury wins on existing budget lines and density of pain. Music
IP is the most technically interesting one but the spend is too
fragmented across labels, distributors, and rights orgs to be
a clean second beachhead. Sports comes before music in our order.
What's the music problem you're closest to?
congrats on the launch, oriane team! how did you cracked inference problem?
Oriane
@a_6 I assume by “inference problem” you’re referring to inference scaling?
In our case, we keep full control over the entire processing pipeline. It does introduce a fair amount of engineering complexity, but once it’s under control, costs don’t scale exponentially anymore.
It becomes more of an upfront investment, combined with a solid and well-designed architecture that allows us to scale efficiently over time. That, along with the right stack (sometimes built in-house), is what enables the video search experience of tomorrow ✨