
Caveman
Why use so many token when few do trick?
251 followers
Why use so many token when few do trick?
251 followers
Caveman cuts ~75% of Claude's output tokens without losing technical accuracy. One-line install for Claude Code, Cursor, Windsurf, Copilot, and more. Four grunt levels, terse commits, one-line PR reviews, and input compression built in. 24.9K stars.













Julius taught Claude to talk like a caveman. 24.9K stars later, it's the most useful meme in developer tooling.
LLMs are verbose by default. Phrases like "I'd be happy to help you with that" and "Let me summarize what I just did" contribute nothing — but burn tokens, slow responses, and push you into usage limits faster. Caveman makes Claude skip the throat-clearing and go straight to the answer. Same fix. 75% less word. Brain still big.
What stands out:
🪨 ~75% output token reduction: Benchmark average 65%, range 22–87% across real coding tasks
⚡ ~3x faster responses: Less token to generate = speed go brrr
🎚️ Four intensity levels: Lite, Full, Ultra, and 文言文 (Classical Chinese) mode
📝 Caveman-commit: Terse commit messages, ≤50 char subject, why over what
🔍 Caveman-review: One-line PR comments: L42: 🔴 bug: user null. Add guard.
🗜️ Caveman-compress: Rewrites your CLAUDE.md into caveman-speak, cutting ~46% of input tokens every session
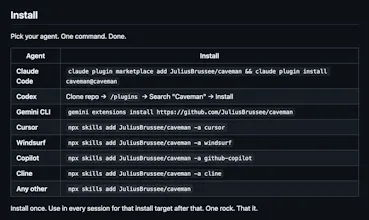
🔌 Works everywhere: Claude Code, Codex, Gemini CLI, Cursor, Windsurf, Cline, Copilot, and 40+ more
🆓 Free, MIT, one-line install
Before and after:
🗣️ Normal Claude (69 tokens): "The reason your React component is re-rendering is likely because you're creating a new object reference on each render cycle..."
🪨 Caveman Claude (19 tokens): "New object ref each render. Inline object prop = new ref = re-render. Wrap in useMemo."
Note: works best for coding tasks. Nuanced responses still need full Claude, and the system prompt loads as input tokens, so net savings vary per use case. A March 2026 paper found brevity constraints improved accuracy by 26 percentage points on certain benchmarks. Verbose not always better.
Perfect for developers hitting usage limits and anyone who wants their AI agent to do the work and shut up about it.
P.S. I hunt the latest and greatest launches in tech, SaaS and AI, follow to be notified → @rohanrecommends
Product Hunt
ConnectMachine
What I like about this is that it gives critical security warnings in full sentences, and the rest of the time it just saves tokens by talking just the essentials.
Heard about this before, looks awesome. Where'd you get the 75% metric from?
I'm using right now. Also I've added to AGENTS.md/CLAUDE.md to always load caveman skill on the first message.
runprompt
Love it! I've been using it for a while together with RTK, and I'm saving a bunch of tokens.
TapRefer
input token is higher! but with cache saves tokens.