We analyzed 6.8 million AI citations across ChatGPT, Gemini, and Perplexity . The finding changed how we think about AI visibility.
The breakdown
First-party websites: 44% of citations
Business listings: 42%
Reviews and social content: 8%
Forums like Reddit: Just 2%
The most impactful sources are the ones you already control . This directly challenges the perception that Reddit and user-generated content dominate AI answers .
The research on how AI systems decide what to trust is clearer than you might think. It comes down to a few core signals that are measurable and actionable.
Citations are the strongest signal. A study from the University of Notre Dame and Deloitte found that simply having citations in an AI response increases user trust significantly even when the citations themselves are random . The presence of sources signals credibility. The act of checking them signals distrust.
E-E-A-T is no longer just Google's framework. It has become the core principle AI systems use to decide what (and who) to trust . AI systems prioritize Experience, Expertise, Authoritativeness, and Trustworthiness when evaluating sources. They look for signs that a real practitioner stands behind the advice detailed bylines, credentials, first-hand narratives, and verifiable experience
Perceived gatekeeping and information completeness matter. Users trust Google because it performs credible gatekeeping . Wikipedia earns trust through collective curation. AI systems look for similar signals: is there evidence of editorial oversight? Is the information comprehensive enough to answer the query completely?
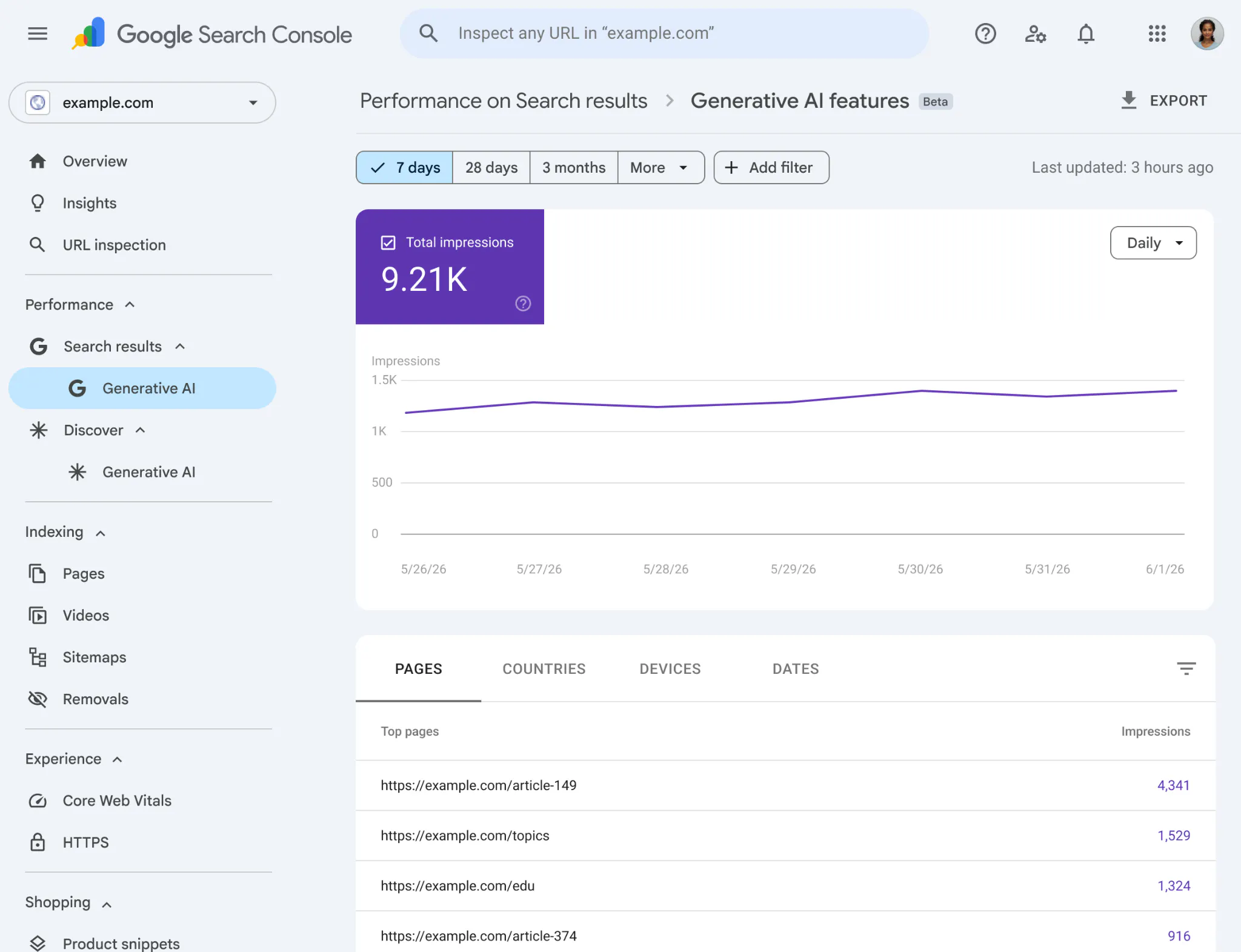
Google just released what SEOs have been asking for: dedicated reports for Generative AI performance in Search Console.
On June 3, 2026, Google announced new Search Console reports specifically for Generative AI features . It's the first time Google has given publishers direct data on how their content performs in AI Overviews, AI Mode, and Generative AI-powered Discover .
February 10, 2026 Microsoft introduced the AI Performance dashboard in Bing Webmaster Tools. It showed website owners how often their content was cited in Copilot, Bing AI summaries, and partner AI integrations. The first time a major search provider gave publishers direct, first party AI citation metrics.
July 7, 2026 Google announced platform properties in Search Console for social and video content. Five months later.
Bing's dashboard was not a fluke. It was a signal.
I was reading Nika's thread here about free vs paid features. Really made me think.
Link: https://www.producthunt.com/p/ge... ( shout-out to @busmark_w_nika ! )
She talks about giving generalized advice for free, but charging for specific, tailored help. That's a good framework. But most product owners figure this out after they build, not before.
Last week, six AI products launched on Product Hunt that share one move. None of them ask users to open a new app. They embed into surfaces people already touch.
Hardware: Dune Keypad (46 upvotes) sits next to your keyboard with Claude integration. Video calls: Mina Meeting Assistant (47 upvotes). Text threads: folk (51 upvotes). Chat windows: Databox MCP (39 upvotes) plugs business data into Claude via Model Context Protocol. Mac autocomplete: Typeahead (22 upvotes).
The pattern is clear: shipping AI as a new app is the slow path. The fast path is grafting onto a surface the user already touches. The cost of building a standalone AI app dropped 90%+. The cost of getting it noticed did not. Surface integration sidesteps the noticing problem because the surface already has users.