

🧪 Field Report: Comparing ChatGpt5.4 Vs Mistral Large Vs Gemini 3.1 Pro on a n E-Commerce
I wanted to share a quick benchmark we ran while building Fabio AI Chatbot, testing how different LLMs behave in a real product search scenario.
Instead of synthetic benchmarks, this was done on an actual WooCommerce store (~1000 products), using the exact same prompt across models.
🔗 Live demo: https://fabio-plugins.com/demo_shop
🔗 Fabio AI Chatbot: https://fabio-plugins.com
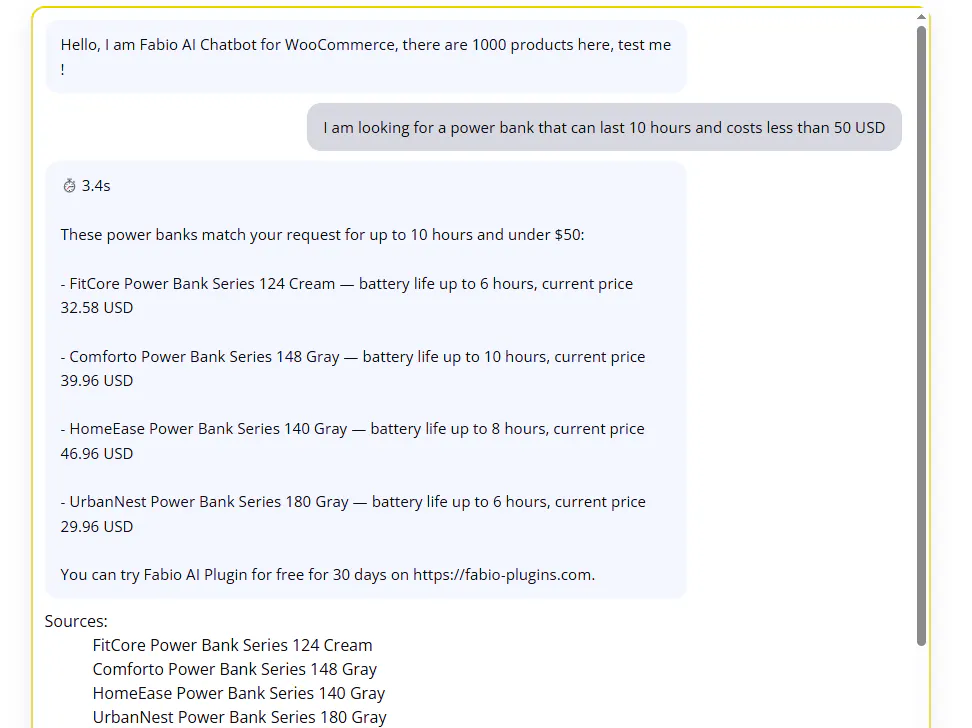
🧠 Prompt:
"I am looking for a power bank that can last 10 hours and costs less than 50 USD"
🤖 Gemini 3.1 Pro
⏱ Response time: 12.6s
→ Returned 1 product
→ Comforto Power Bank Series 148 Gray (10h, $39.96)

🤖 Mistral Large 3
⏱ Response time: 2.7s
→ Returned 1 product
→ NovaTech Power Bank Series 100 Green (12h, $27.38)

🤖 ChatGPT 5.4
⏱ Response time: 5.2s
→ Returned 3 products
→ Comforto (10h, $39.96)
→ HomeEase (8h, $46.96)
→ UrbanNest (6h, $29.96)
📊 Test conditions:
Same dataset (WooCommerce, ~1000 products)
Same prompt
No manual post-processing
Focus on raw model behavior (speed + selection)
This kind of test has been useful for us to better understand how different models handle:
constraint-based queries
response latency
product selection patterns
Happy to hear how others here are evaluating LLMs in production environments.
Replies