
Cursor
AI coding agent
5.0•897 reviews•50K followers
AI coding agent
5.0•897 reviews•50K followers
Cursor is the best way to build ambitious software.
This is the 10th launch from Cursor. View more

Cursor for iOS
Launched this week
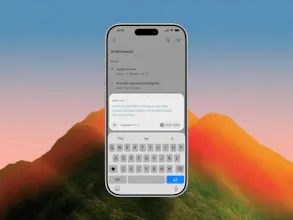
Cursor is now available as a native iOS app in public beta, so you can build from anywhere.
Until now, developers have worked around the limits of their local machines, keeping laptops half-open and caffeinated everywhere they go.
With Cursor for iOS, you can launch always-on agents in the cloud, or control agents running on your computer from your phone. Kick them off when ideas strike, get notified when work is ready for review, and merge PRs on the go.



Launch Team






 Claude Code
Claude Code
 Windsurf
Windsurf opencode
opencode
Cursor for iOS
Hey all! I'm Chris, Mobile Lead at Cursor, excited to hear what you think of our new app. We'll be around to answer questions throughout the day!
@cbrauchli I really hope you announce the Android version very soon
Cursor
@ayoub3bidi Android is planned. :)
The mobile part I keep thinking about is the review step. Kicking off agents from a phone is easy, but merging on the go means approving diffs on a screen where you can't really read a diff, and every time we've moved approvals to a phone people start rubber-stamping. So the agent's summary of what it changed becomes the real gate, not the diff. Does the app surface anything risk-ranked, like this touched auth or deleted tests, or is review just scrolling the raw changes?
Cursor
@dipankar_sarkar We thought very carefully about this since phone screens are smaller and have less real estate. The diff view is more focused and designed for mobile, so hope you check it out and let us know what you think! Agents also produce demos, screenshots, and logs as artifacts for your review.
Artifacts as the review surface instead of the raw diff matches what we landed on too. The thing that decides whether they actually gate: are the screenshots and logs from an independent run, or the agent narrating its own work? We had demo clips that looked green because the agent captured the happy path it just wrote, and the regression sat one screen over. Tying review to CI output like you mentioned to Prashant is the version I'd trust from a phone.
Cursor
@dipankar_sarkar if you're looking for an independent run, you could set up an automation that works like a CI check!
Voice input from the phone sounds useful, but I’d be nervous sending a messy spoken prompt straight to an agent. Does Cursor turn it into an editable brief first, or does the agent start from the raw voice request?
Cursor for iOS
@novamaker01 You get editable text from your voice request first! Allows you to edit any of the text before you send to the agent.
Congrats on the iOS launch! 🚀
The most useful part for me is not full coding on mobile, but starting agents, checking progress, and reviewing work while away from the laptop.
Curious how Cursor handles mobile review safety. Does it highlight risky changes like auth, payments, database migrations, or deleted tests before someone approves or merges from a small screen?
Cursor for iOS
@prashant_patil14 Would highly recommend turning on Bugbot if you're interested in code review by Cursor! In our own internal dev setup, we have Bugbot give each PR a risk rating.
Cursor
@prashant_patil14 thanks, Prashant! The review on mobile is focused on formal blockers to merge like CI and reviewers. More coming soon to make this a more complete experience.
Can I switch seamlessly between an agent running in the cloud and one running on my local machine, or do they have separate workflows?
Cursor
@nitesh_kumar98 In the desktop app, you can hand off a session between cloud and local seamlessly. It's basically the same workflow running in different environments with some differences in capabilities since giving agents their own isolated VM is a big unlock.
The mobile angle for coding agents is interesting, especially with Cursor already being associated with dev workflows. How much of the iOS experience is meant for actually editing code versus steering an agent through prompts, reviews, and approvals? I’d also be curious whether the app is optimized for existing projects or if it supports starting lightweight tasks from scratch while on the go.
Cursor
@crystalmei at Cursor, our engineers don't manually edit code much anymore! We're using the mobile app to steer and manage agents—both for existing projects and new ones that we kick off on the go.