

PDF Data Workbench - Early product feedback appreciated
Hi PH,
I’d appreciate some early feedback on a PDF data tool I’ve spent the last three months building. My main frustration with existing solutions wasn't necessarily their initial accuracy, but rather the total lack of feedback loops.
Specifically, I found that most tools I have used:
Prevented quick fixes: You couldn't correct extraction or markdown errors directly alongside the source document. If there was one, it's a raw markdown editor that is hard to use on tables.
Lacked "hybrid" extraction: It was difficult to combine techniques—for example, using Vision AI for layout (which can hallucinate) alongside traditional OCR for character accuracy (which lacks structure). It's important to test this be cost-effective too.
Lacked focus: There was no way to tell the tool to prioritize specific pages over the rest of the document.
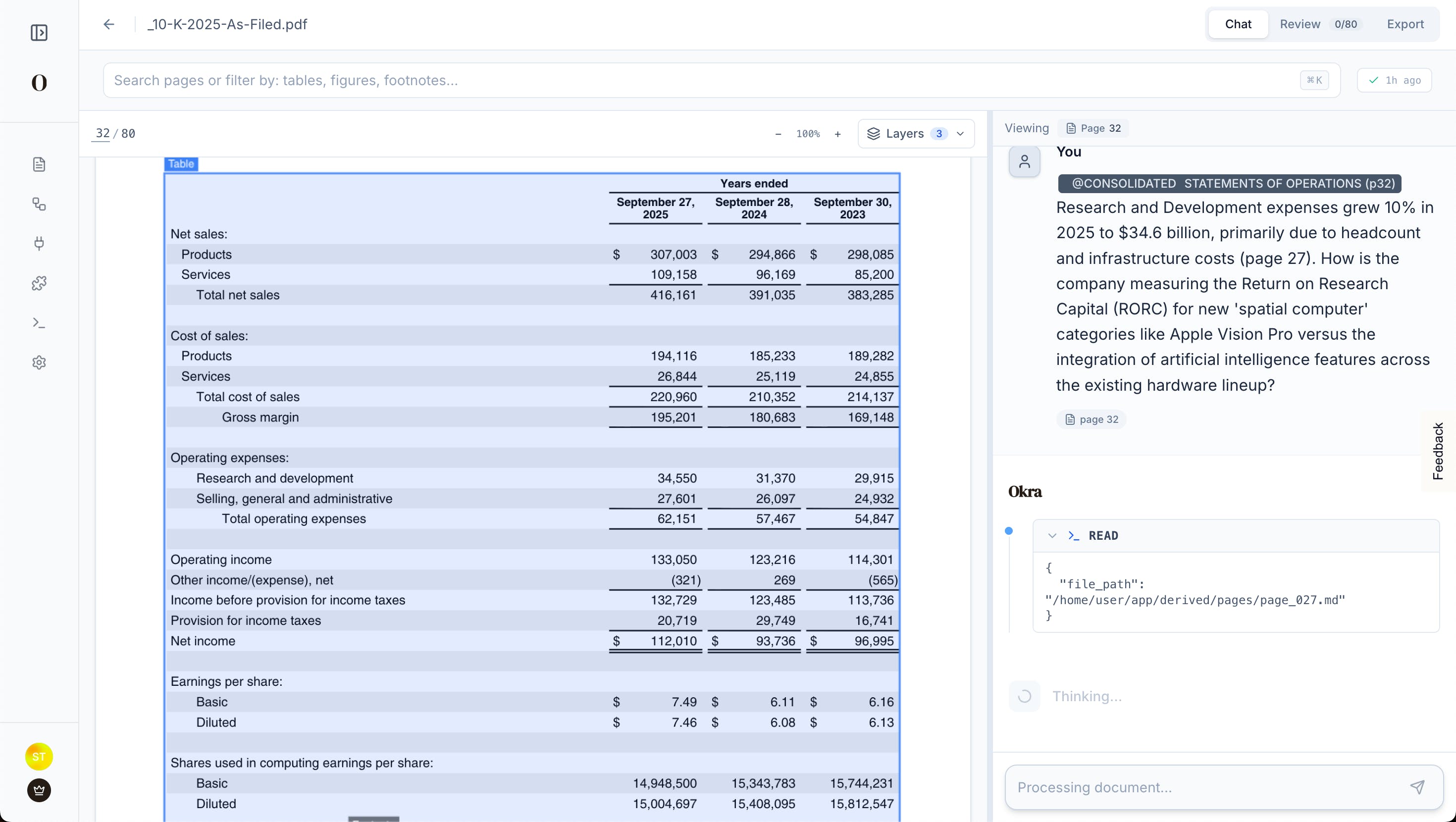
I plan to launch in a few days and would love for you to test it with your most complex PDFs—think public earnings reports, long manuals, etc. All OCR and Agent usage is free during the launch phase.
Thank you so much for the support!
Steven
Replies