The Innovation: Most transformers suffer from "semantic friction" in standard attention. I replaced the attention mechanism with a native E8 Root System Lattice. By leveraging the densest sphere packing in 8D, LILA-E8 achieves a state of "Geometric Resonance" that standard architectures simply cannot reach at this scale.
For those who requested the math: The Master Projection Framework is now live. Equation (2) is the physics; LILA-E8 is the neural implementation. Audit the Source. https://doi.org/10.5281/zenodo.1...
Geometric Attention Transformer with the E8 Root System: Lila-E8 (Lie Lattice Attention Language Model) -
The Geometry of Scale: Standard transformers scale by adding more 'Euclidean soup' (more parameters). LILA-E8 scales by increasing the packing density of the manifold. If the 8D version crunches 40M parameters into SOTA performance.
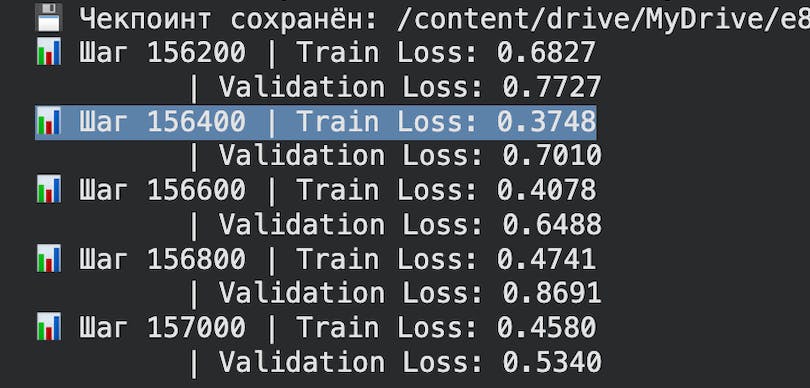
🚀 Results at 200k steps:
- Model: 40M parameters.
- Performance: 0.37 Train / 0.44 Val Loss
- Stability:1000+ tokens without semantic loops.

![Anatolii [ aka @Bootstraptor ]](https://ph-avatars.imgix.net/428688/0c610880-d857-4865-b071-bb51a31e1741.png?auto=compress,format&codec=mozjpeg&cs=strip&fit=crop&frame=1&h=16&w=16)