
clawsec
clawsec verifies AI agent skills before you install them
8 followers
clawsec verifies AI agent skills before you install them
8 followers
clawsec verifies AI agent skills before you install them. Our multi-stage pipeline - YARA pattern detection, LLM semantic analysis, and false positive filtering - catches prompt injections, credential harvesting, and hidden malicious code. Paste a skill, get a trust score. No signup needed.




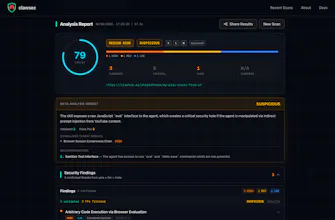


@clawsecdev try running this on the top installed clawhub skills and share their scores with the community, could be a game changer for your gtm
can agents directly install the clawsec skill to verify other skills or is this on web interface only ?