

Context Evaluator
Detect and fix issues in your AGENTS.md, CLAUDE.md, and more
21 followers
Detect and fix issues in your AGENTS.md, CLAUDE.md, and more
21 followers
Bootstrapping context files is easy; keeping them accurate is not. Context-Evaluator is an open-source scanner for your AGENTS.md, CLAUDE.md, and other instruction files, along with skills to detect content quality issues, missing setup steps, context gaps, and mismatches between documentation and code. With Context-Evaluator, clean the context files used by our AI Coding agents so they're up to date and cover the relevant information. Support Claude Code, Cursor, and GitHub Copilot.
Interactive
Free
Launch Team / Built With



Packmind Open Source
Hi there 👋
I'm Cédric, CTO at Packmind.
The other day, I was using Claude Code on my project and was surprised by a command it tried to execute to run the test suite.
I realized that maybe the context in my "CLAUDE.md" files was missing, unclear, or, worse, outdated.
Indeed, creating a "CLAUDE.md", "AGENTS.md", or any other instruction file supported by coding agents such as GitHub Copilot, Claude Code, or Cursor is quite easy.
Claude Code lets you run "/init" to create a CLAUDE.md.
In 2026, code is created faster than ever. Architecture moves forward at a high pace. Refactoring as well.
If you used to struggle to keep up-to-date documentation in your Notion, Confluence, or other wiki tool, you’ll face the same challenges with your AI Coding Agent context files.
I've shared some findings from open-source projects about these challenges in a recent blog post.
So here's the challenge: how do we keep our context documentation up to date?
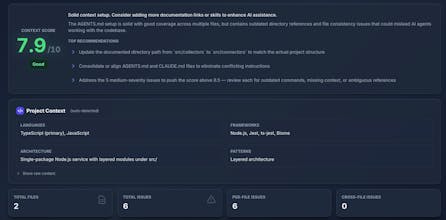
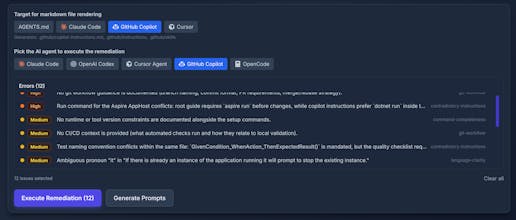
At Packmind, we’ve built context-evaluator as an open-source tool capable of:
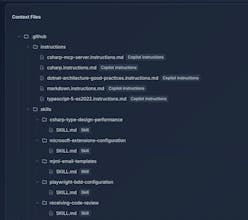
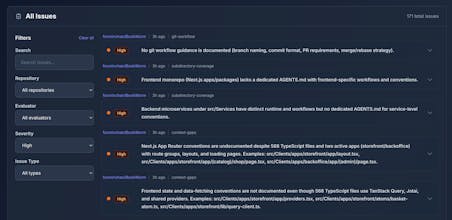
Scanning your Git repos to analyze AI coding agent context files
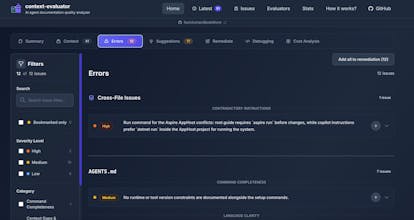
Identifying current errors (such as contradictory or outdated instructions)
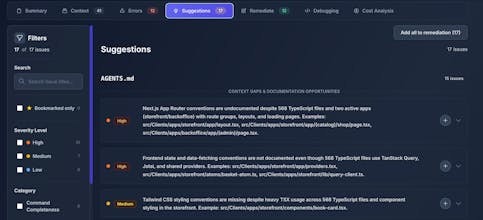
Suggesting context gaps to fill (such as much React code in the codebase without any guidelines)
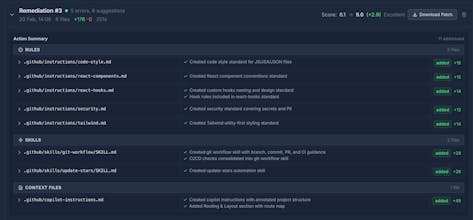
Creating remediations to improve your current context
Context-Evaluator runs the coding agent CLI in your repo, along with dedicated evaluation prompts, to trigger areas for improvement.
Run it online with our public page, or run it locally with your favorite coding agent CLI (Claude Code, GitHub Copilot, Cursor, OpenCode, and OpenAI Codex supported).
An AI coding agent is only as smart as the last time your context was reviewed, right?