
The story behind Senthor, and what we built while waiting for the market to catch up

14 months ago we started building Senthor convinced that AI companies would eventually have to pay for the content they scrape.
We were right. We were just early.😅
The product is simple: if you run a website, a blog, a media outlet, anything that produces content, AI agents are crawling you every day. They ignore your robots.txt, they take your articles, your PDFs, your images, your videos, and they train on all of it for free.
Senthor sits at the server level and changes that. It fingerprints every AI agent in real time, tells you exactly what they're taking and when, and lets you decide: block them, allow them, or charge them. Pay-per-crawl. Machine-to-machine micropayments, no code change needed.
French VCs told us "AIs will never pay for content." Then Reddit signed a $60M deal with OpenAI. Then AWS shipped native x402 pay-per-crawl support. The thesis validated itself, just on someone else's timeline.
We're now onboarding our first paying customers. The data we generate on AI traffic has real value beyond monetization: understanding which AI reads what, how often, which formats they prefer.
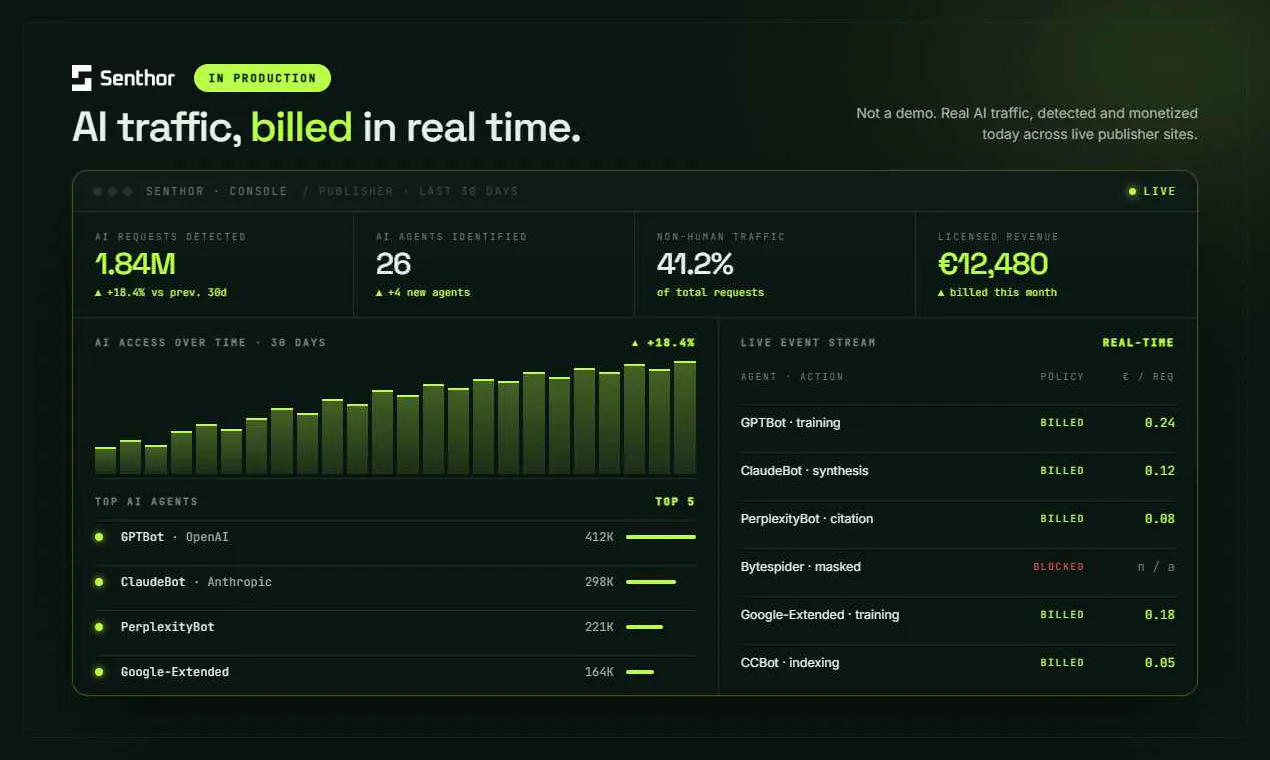
If you run a content-heavy site and you're curious about what AI agents are actually doing on your pages, happy to chat 😎
Replies