

Do serverless platforms still underestimate observability?

One thing we think is still underrated in compute platforms is observability.
A lot of infra feels simple until something breaks in production. A webhook fails, a cron job doesn’t run, an AI agent gets stuck, or a function times out even though it worked fine in testing.
That is where “just running code” stops being enough.
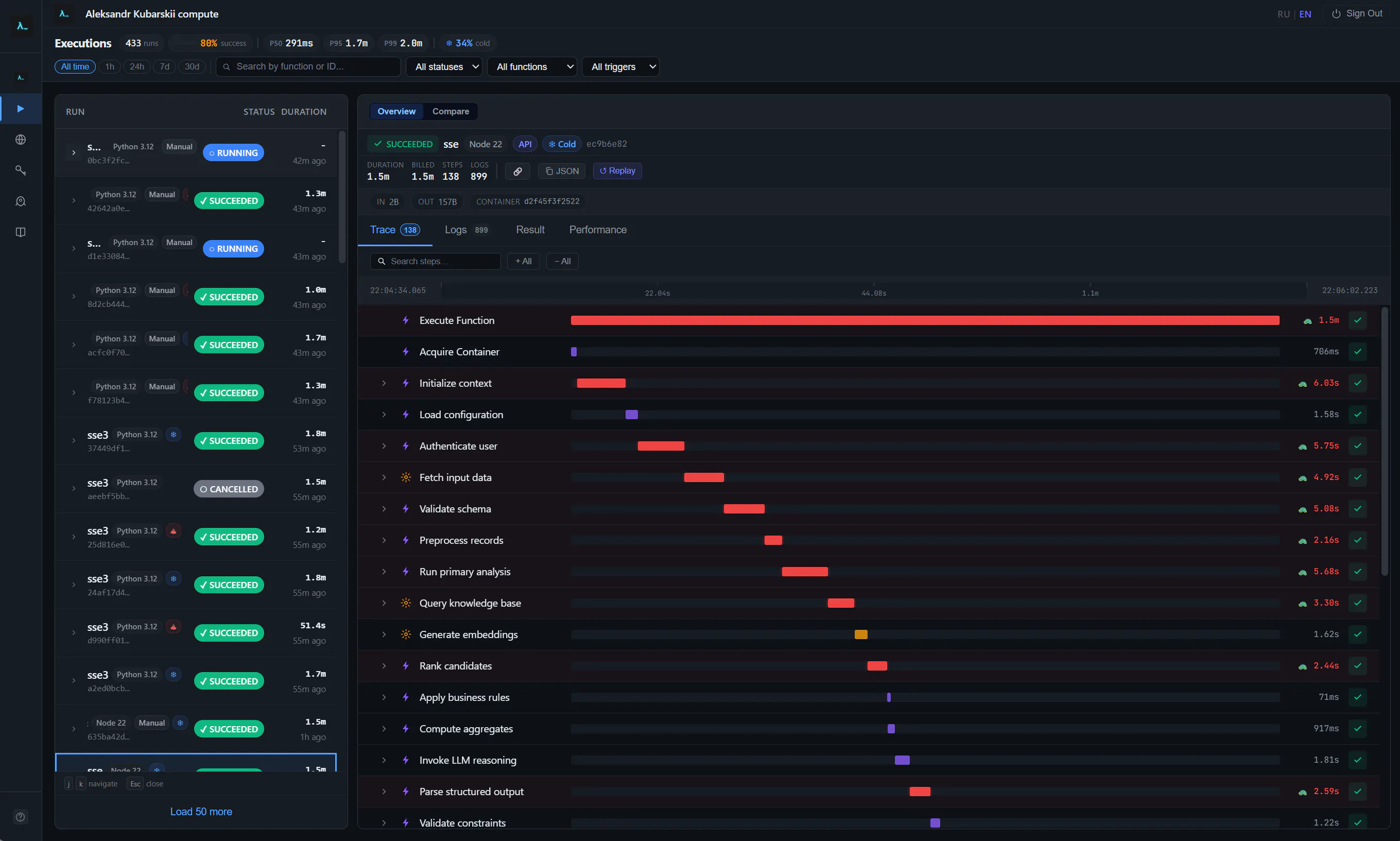
In Inquir Compute, we think logs and observability are a core part of the product, because developers need more than raw output. They need context: what triggered the execution, which route or webhook was involved, how long it ran, whether it retried, and what happened right before the failure.
Curious how others here think about this: when you evaluate a compute/serverless platform, do you see observability as a core feature or still more like a nice-to-have?
And check out how it looks on the platform:
Replies