
 •
•3mo ago
RAG-powered Global Assistant
One of the most interesting upgrades I recently shipped in Derisqo was a RAG-powered Global Assistant.
The app already lets users upload meetings and documents, but I wanted the AI to answer from the user s actual workspace context not just from a generic model response.
So I built a retrieval pipeline for the workspace-wide assistant: meetings and documents are processed, chunked, embedded, stored in pgvector, and semantically retrieved whenever the user asks a question in global chat.
In practice, the assistant searches across a user s meetings and documents, pulls the most relevant context, and uses that retrieved information to generate a more grounded response.
A few things I focused on:
Speaker-aware chunking for meeting transcripts
Section-aware chunking for documents
Cross-resource semantic retrieval
Prompt grounding with retrieved context and source labels
The difference is subtle but powerful: answers are no longer generic they re context-aware and traceable back to your own data.
 •
•5mo ago
Real-time progress tracking implemented
Processing a 90-minute meeting isn t instant.
And staring at a spinner with zero context feels broken.
So this week, I shipped real-time progress tracking.
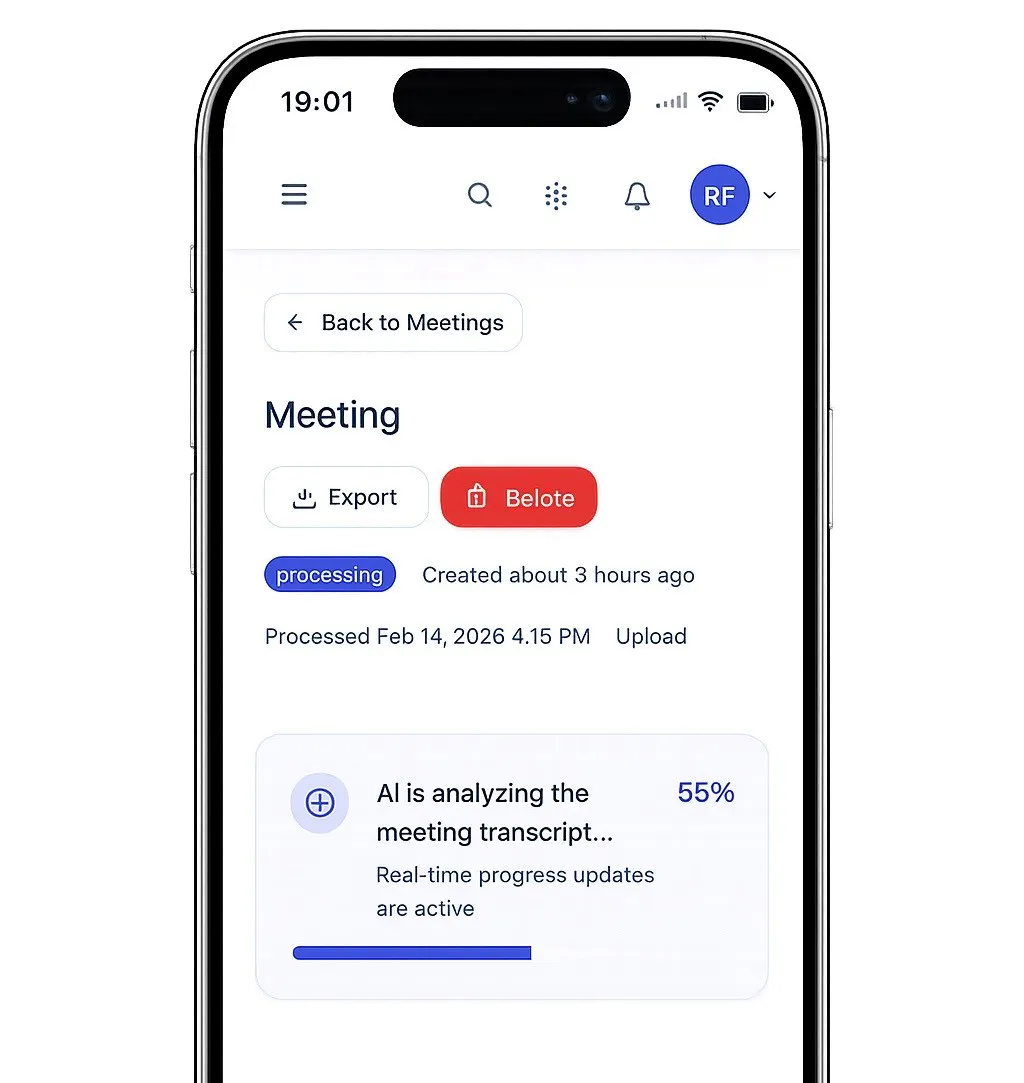
Now, instead of guessing, you see exactly what s happening:
Audio compression (reduces upload time)
Transcription progress (Whisper AI)
Analysis steps (decisions, action items, risks)
Estimated completion time
No more wondering if it failed.
No more refreshing the page.
Just transparency.
Under the hood, this required:
Redis-backed job queue (BullMQ)
Server-Sent Events for live updates
Multi-instance support for proper scaling
Small UX change.
Huge difference in perceived speed.
If you re processing long meetings or large contracts,
waiting isn t the problem.
Uncertainty is.
•6mo ago