Launched this week

VisibAI
Are you in AI answers? Find out and fix it in minutes
404 followers
Are you in AI answers? Find out and fix it in minutes
404 followers
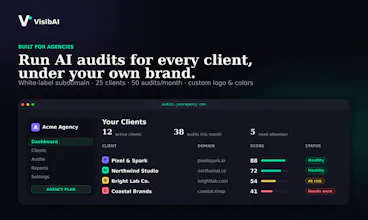
VisibAI shows whether your business appears when people ask AI for recommendations, and helps you fix it. It runs queries across six AI platforms (ChatGPT, Perplexity, Claude, Gemini, Mistral, You.com), scores your visibility 0-100, reveals which competitors show up instead, and returns a prioritized fix list plus ready-to-ship fix files and a branded report. One-off audits or monthly tracking. White-label for agencies. EU-hosted and GDPR-native.








VisibAI
Hi everyone 👋
I'm Francesco, founder of VisibAI. I spent years selling SaaS across Europe and watched search behaviour move from Google to AI assistants.
VisibAI tells you whether ChatGPT, Perplexity, Claude and other AI assistants recommend your business when someone asks for one. Then it shows you exactly how to improve.
The problem: for years everyone optimised for Google. Now people open ChatGPT or Perplexity and just ask for a recommendation, and most businesses have no idea whether they show up in those answers.
The solution: a score on its own does not help, so we give you the full benchmark. VisibAI runs automated queries across six AI platforms (ChatGPT, Perplexity, Claude, Gemini, Mistral, You.com) and shows you:
a visibility score from 0 to 100
how often you are mentioned or cited
which competitors appear instead of you
Then it tells you how to fix it: a prioritised fix list, ready-to-use fix files (robots.txt, schema, FAQ), and an AI action plan.
The benefit: you stop guessing. You see where you stand against competitors in AI answers, and you get concrete steps to climb. Start with a free audit, run a one-off report with no subscription, or go monthly for ongoing tracking and competitor monitoring.
Who it is for:
Brands that want to be the name AI recommends in their category
Agencies, who can white-label the whole platform under their own subdomain and brand, and run it for every client
You can try it here: https://getvisibai.com
Built in the EU and GDPR-native, which matters to a lot of the teams we work with.
Happy to answer any questions 🙌
PicWish
@francesco2689 how do you handle non determinism in llm answers like if chatgpt gives a different answer on next refresh, does it average the score?
VisibAI
@mohsinproduct
Good question.
Right now it’s a single-shot snapshot per query, not averaged across multiple runs, so you’re right that a refresh can shift individual answers.
We handle the variance two ways: the score leans on patterns across 30 queries and 6 engines rather than any one answer, so a single flip moves it only slightly, and we re-scan over time so you see the trend rather than treating one run as absolute.
Multi-sampling each query and averaging into the score is high on the build list, it’s the cleanest fix for exactly this, and it’s coming.
PicWish
@francesco2689 makes sense
Really like the framing here. The thing I keep running into with AI visibility is that "not showing up" almost always traces back to plain old ranking and authority. From what I've seen the answer engines mostly pull from pages already sitting in the top 20 for a query, so a page down at position 40 can be perfectly structured and still never get cited.
Does VisibAI separate those two cases? As in "you're invisible because your content isn't quotable" vs "you're invisible because you're not ranking high enough to be in the pool yet." The fix is completely different depending on which one it is, and that's the part I'd personally find most useful.
VisibAI
the six-platform sweep is the right call - visibility on ChatGPT vs Perplexity vs Claude can look completely different because each pulls from different sources with different recency windows. a score of 60 on one and 20 on another tells you something specific and actionable. the part I'm most curious about: when you show "how to fix it" - is that primarily schema/llms.txt/content changes, or are you also surfacing the competitor citations that are showing up instead of you? knowing who's displacing you in AI answers is probably the most valuable signal for figuring out what content you're actually missing.
VisibAI
The interesting part isn't the score, it's knowing what to do next and whether it actually worked. How do you decide which queries to test so they reflect real buyer behavior? And once a team implements the fixes, what's the feedback loop? AI visibility doesn't have a Search Console equivalent, so I'm curious how you help teams know they're actually improving. Congrats on the launch!
VisibAI
@jared_salois two great questions =)
Queries: we generate them from your industry, sub-category and buyer context, then split by funnel stage (awareness, consideration, decision) so they mirror how real buyers actually ask, not just branded terms. You can edit or add your own before the run.
Feedback loop: you're right there's no Search Console for this, so we are it. We re-scan over time and show which queries flipped and on which engine after you apply fixes. The clean before/after attribution is the piece I'm actively tightening right now, since proving it worked is the whole point.
The hard part with a visibility score like this is LLM nondeterminism — ask ChatGPT the same recommendation query twice and you can get different brands back. Do you sample each query multiple times and average into the 0-100, or is it a single-shot snapshot? And are the six platforms hit through official APIs or logged-in scraping, since that changes whether the result matches what a real signed-in user actually sees.
VisibAI
@noctis06 thank you for your comment!
Sampling: single-shot snapshot today, not averaged. You're right that non-determinism means one run isn't gospel, so multi-sampling and averaging is high on my list. For now we re-scan over time to smooth the noise.
Access: official APIs, not scraping. Reproducible and clean, but it's the API model's answer, not a pixel-perfect match to a signed-in app session. Treat it as a consistent proxy for the model's knowledge.
Makes sense — official APIs over scraping is the right call for reproducibility, and framing it as a proxy for the model's knowledge rather than a live signed-in session is honest. On the re-scan-over-time approach: do you surface the variance to the user, or just the latest smoothed score? A confidence band would tell me whether a 1-point move is real movement or just run-to-run noise.
VisibAI
@noctis06
Spot on, and you've named the exact gap. Right now we surface the latest score and the trend line, but not a variance or confidence band, so today a 1-point move and real movement look the same, which isn't good enough.
A confidence interval is the right answer, and it's the natural payoff of the multi-sampling work: once each query is sampled several times, we get a distribution per query, which gives both a more stable score and the band around it to tell signal from run-to-run noise.
That's the direction this is heading. Appreciate you pushing on it, this is exactly the kind of rigor the category needs.
I like that this starts with a one-time audit instead of asking teams to commit to another monthly SEO tool. My main trust question is reproducibility: does the report show the exact prompts, platform, timestamp, and raw answers behind the score so a team can verify what changed after applying fixes?
VisibAI
@novamaker01 hey, i went with the one-time angle and agree that it's better that way.
Hey,
Congrats for the launch.
Quick feedback on my first test so far:
30% of my traffic is coming from GEO/AEO
We've done quite extensive work on that and continue
But from what your app tell us: score 49/100
And everything is 0% , not passed, etc.
I don't believe that nothing can be found about us and we get 49/100 score. How is this related?
Like I literally didn't learn anything from it and will not be willing to go further or even paid for that yet.
Hope that's helping you guys improve!
VisibAI
@francesco2689 Done!
Thanks for taking time as well, appreciate that you appreciate raw feedback and get involved into it :)
VisibAI
@florent_duthoit just replied back to your email
@florent_duthoit i'd appreciate the feedback as well!