Launching today

Tokenwise
A smart LLM proxy that shows where you're overpaying
86 followers
A smart LLM proxy that shows where you're overpaying
86 followers
Tokenwise is a one-line LLM proxy (OpenAI-compatible baseURL) for makers and small teams. It learns from your real requests, shows exactly where you're overpaying, proven with quality checks on your own traffic, not public benchmark, and lets you apply the fix in one click while it verifies the savings in real dollars.





Tokenwise
@tofil congrats on the launch Theo, this is very useful (I can never match the advertised input/output costs to my work either). What's the overhead fo r this and how deep does it go reporting wise?
Tokenwise
Thanks @zolani_matebese , really appreciate it
On overhead: the proxy runs on Cloudflare Workers at the edge, so we add ~30-50ms p50 in most regions (the actual provider call dominates latency anyway).
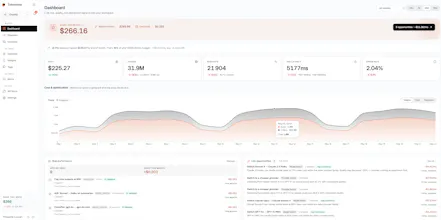
On reporting depth, here's what you get per request:
Exact cost (we re-tokenize and apply current pricing tables, so the "I can never match the bill" problem you mentioned goes away)
Input/output token counts, latency (TTFT + total), status, error type if any
Full prompt/response payload if you opt-in per project (off by default for privacy)
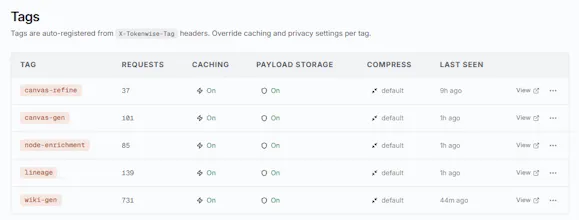
Model + provider + project + custom tags you set
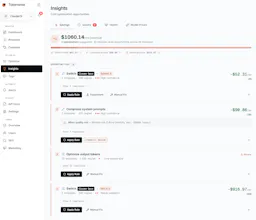
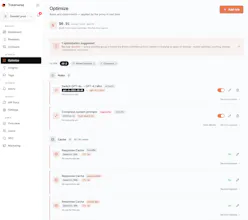
And on top of that, aggregations by prompt template (we cluster semantically), recommendations with quality proof on your own data, and a "saved this month" counter that tracks the impact of applied recos in real $.
Observe-only is probably where I’d start, especially for Claude Code spend. The scary part is the “apply” step.
Before swapping a model, does Tokenwise show exactly which traffic it will touch, and is there an easy rollback?
Tokenwise
@novamaker01
Here's how it works:
Before apply, you see exactly:
The prompt template(s) affected (with a sample of recent requests)
The estimated traffic % (e.g. "this rule will route ~12% of your project's requests")
Optional scoping: limit to a tag, a project, exclude certain endpoints
The "apply" doesn't blindly cutover. By default it runs as an A/B split, say 10% of matching traffic on the new model and you watch the quality scores + latency + cost for 24h before deciding to ramp to 100%. You can also choose immediate cutover if you prefer.
mailX by mailwarm
Does Tokenwise break down coding agent spend by session or only by model?
Tokenwise
Hey @bengeekly not by session yet, but the workaround works well today.
You can pass a tag (or session ID) on each request via the X-Tokenwise-Tags header, and Tokenwise clusters all requests sharing that tag, so for a coding agent you'd set X-Tokenwise-Tags: session-{conversationId} and see the full cost breakdown per session: total spend, which model, which prompt template (we cluster those semantically too), outliers, etc.
First-class sessions view (auto-grouped, no header needed) is on the short roadmap.