Launched this week

Signspell
Real-time ASL alphabet recognition in py ,pip install and go
70 followers
Real-time ASL alphabet recognition in py ,pip install and go
70 followers
Signspell is an open-source Python package that recognises the American Sign Language fingerspelling alphabet live from your webcam. It works as both a command-line tool and an importable library. Install it, run one command, and start signing letters that appear on screen.Built with MediaPipe hand tracking and an LSTM model, it runs smoothly on an ordinary laptop CPU, no GPU required. MIT licensed and built for developers, students, and educators curious about computer vision and accessibility.

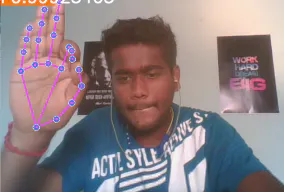





Signspell
Shipping it as both a CLI and an importable library behind a plain pip install is the right call here, since most webcam ML demos end up as a clone-the-repo-and-pray Gradio app you cannot embed. As a library, what does the public API actually surface: do I get per-frame hand landmarks plus the predicted letter as a callback I can pipe into my own loop, or am I locked to your capture window? And since this is MediaPipe running on-device, does any frame or telemetry ever leave the machine, or is the webcam stream guaranteed fully local with nothing hitting a network?
Signspell
@hi_i_am_mimo Yes Valeria.
It is fully local .
Nothing hits the network
Fully local with nothing leaving the machine settles the privacy half, thanks. The other half I'm still unsure on: as an imported library, do I get per-frame hand landmarks plus the predicted letter as a callback I can pipe into my own loop, or am I tied to your capture window? And with the custom model path, is the inference interface stable enough that I could drop in my own fingerspelling model without touching your capture code?
Signspell
@hi_i_am_mimo Great questions — and yes to both, because the capture window and the recognition engine are deliberately separate.
On per-frame access: you're not tied to the capture window at all. The Recognizer class is headless — you feed it frames from your own loop and it returns the prediction.
On dropping in your own model: yes, that's a first-class use case. You pass a model path either on the CLI or to the Recognizer
Headless Recognizer you feed your own frames is exactly the shape I wanted, that makes it embeddable. Last one: alongside the predicted letter, does the Recognizer also hand back the raw MediaPipe per-frame landmarks and a confidence score, so I can threshold and debounce noisy frames myself before committing to a letter? Fingerspelling tends to flicker between similar handshapes, so frame-level confidence is what I'd build the smoothing on.
Curious how well does the LSTM model generalize across different hand sizes, skin tones, and lighting conditions in real-world webcam setups?
Signspell
@crystalmei Sure.
It does a decent job.
Please do try it up.
Signspell
FAQs
Does it need a GPU? → No, runs on an ordinary laptop CPU.
What Python versions? → 3.9, 3.10, 3.11 (TensorFlow 2.15 requirement).
Is it a full sign language translator? → No, it does fingerspelling; honest about scope.
Can I use my own model? → Yes, via custom model path.
Is it open source? → Yes, MIT licensed.