Launched this week

Polygraph
Let AI agents see cross repo and maintain session memory.
5.0•10 reviews•312 followers
Let AI agents see cross repo and maintain session memory.
5.0•10 reviews•312 followers
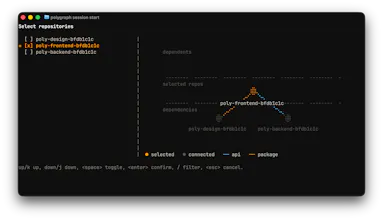
AI coding agents are limited to how autonomously they can work because they have no model of the codebase as a whole. Polygraph is a meta-harness that gives agents what they're missing: Visibility across every repo boundary and memory that survives the session. Connect all your repos, private and public, into a unified dependency graph without moving any code. Resume, reference or build on any session created by any developer, on another machine, even on different agents.















Polygraph
Our founders, Jeff Cross and Victor Savkin, have been building monorepo tooling for over a decade. In the last few years we've noticed that the ergonomics of monorepos have been especially great with AI agents. All your code visible in one place, allowing you or your agents to quickly see the full context it needs to make decisions that won't break your CI when it comes time to merge.
We wanted to bring this to the whole developer tooling community because we know even if some teams use monorepos, it's not realistic to have an entire org on one (unless you're Google.) It started by building a dependency graph - a sort of synthetic monorepo - and then we had to tackle agentic amnesia. Agents are great, but having to re-explain yourself or losing context sucks. Like a game of telephone, it's never the same as being able to stay in session.
We built Polygraph for:
Individual devs: If you're deep in a feature that touches 3 repos, Polygraph will set up all 3 in a single session, manage CI across them, and keep a record of everything your agent did. A week later if you need to fix a bug or go on PTO and want to hand it off to a teammate, they can continue it on their machine without any loss.
Teams across services: If a change to a shared library touches 5 downstream repos, Polygraph lets your agent validate that change across all 5 before a single PR is opened. It then opens and manages the cross-repo PRs and CI together, so the whole change moves as one unit.
Thanks for checking out our new product - we'd love to get your feedback!
The session memory piece is the hard part - most AI coding tools treat every conversation as stateless, which means re-explaining the same codebase context over and over. The cross-repo visibility is interesting because naively including every repo would blow the context window, so curious how you're handling that tradeoff. Is it doing dependency graph traversal to selectively pull in relevant context, or more of a semantic similarity search over chunked code? And does the session memory persist across different agent frameworks (Claude Code, Cursor, etc.) or is it scoped to one at a time?
Polygraph
@galdayan thanks for checking out the launch!
So the cross-repo part has three parts
- first we have a dep graph and we index all repos semantically so an agent can find relevant repos for its task and include them in the session
- then in order to learn things across multiple repos, polygraph will actually check out the repo locally and delegate subagents to work inside them so we have the actual code in front of us, not just embeddings etc. This also includes any OSS repo btw so you can easily pull them into your sessions
- lastly, after making changes in one or more repos, Polygraph can make PRs across them all, track CI statuses in a single place and coordinate follow ups as well as link npm packages together so you can test out changes from one repo in another one that depends on it
The session memory persists across all agent frameworks, we store normalized versions of the transcripts so you can take a session a colleague started in claude and resume it in codex.
The part that grabs me is resuming a session created by another developer on a different machine and even a different agent, since agentic amnesia across a team is exactly where my context keeps dying. Where does that shared session memory plus the cross-repo dependency graph actually live, is it hosted in Polygraph's cloud, or stored locally and synced between machines? And since you connect private repos without moving any code, is the graph built by indexing repo contents server-side, or does indexing stay local with only graph metadata leaving the machine?
@noctis06
A bit of both. Hosted on cloud and stored local on machines where session is started or resumed. Technically, we don’t support / promote 1+ machines working on a session simultaneously at the moment. Data going to Polygraph API can be persisted on first come first serve basis but no reactive sync between the local machines.
Index is assigned to repositories as they’re connected (ensuring the users have access to the repos to connect) and scheduled to run on the server. It is once per day or can be triggered on demand on Polygraph UI
That clears it up, thanks. Since indexing is server-side and runs about once a day unless I trigger it, when I resume a session mid-task does the dependency graph reflect my uncommitted local changes, or only the last indexed snapshot of the repo? Trying to gauge how stale the cross-repo context can get on a fast-moving branch between runs.
@noctis06 Only the last indexed snapshot of the repo. Since the indexing is run on Polygraph's cloud, we pull the latest from the repo via the repo's default branch to index against, uncommitted local changes won't be reflected.
That said, can you elaborate a little bit more on "when I resume a session mid-task", what is your use-case/workflow here?
This is a really interesting idea. Cross-repo context is one of the biggest limitations I've run into with AI coding agents.
I'm curious: how do you keep the dependency graph accurate as repositories evolve independently? Is it updated continuously from Git changes, or rebuilt on demand before an agent starts working?
Congrats on the launch! 🚀
Polygraph
@prashant_patil14 thanks for the feedback and checking out Polygraph!
The repository graph is updated once a day or on demand when users request it since inter-repo dependencies aren't something that changes super often, it's more of a slow evolution.
The graph of sessions and code changes is updated more regularly, whenever new git changes come in or PRs are created :)
Hope that helps, happy to chat more about it
love this. agent amnesia is easily one of biggest pain right now when working across multiple repos.
quick question, what happens if another developer pushes new code to a repo while my AI agent is still working on it? does the agent realize the code changed, or do I have to restart the session? great launch guys.
Polygraph
@wilder_dev thanks for the kind words, Erik!
Polygraph doesn't ship anything here beyond what git already has. So you can make a PR and that might just be unaffected by the new changes.
What polygraph does have though is CI monitoring and skills for helping your agent fix CI across all the different PRs across repos. So if there's a merge conflict, polygraph can help you figure it out and make any further updates that are required after resolving the conflict.
@max_kless2 got it, that makes perfect sense. thanks for clarifying!
Polygraph
@wilder_dev you got it! Let me know if you have any other questions and try it out!! :P
https://app.trypolygraph.com/
Cross repo visibility plus resumable sessions is a real unlock. A session snapshot carries state and code from several private repos, and another developer can pick it up on their own machine. Does the snapshot respect per repo permissions, so resuming a session never hands someone context from a repo they aren't allowed to see?
Polygraph
@angelika_dev yes! You can only interact with sessions for which you have access to all the repos.
If all the repos are open-source, you can generate a share link so external ppl can have a look at your session as well (like for repros in bug reports for example).
The session resume across agents is the part I want most. I work across two repos and every time I switch context, I lose whatever the agent learned about the other one. Feels like starting from scratch each morning. When you normalize transcripts across different agents, does the session carry over tool-specific context too, like file edits that happened but weren't committed yet?
@yannikga Yes. The actual uncommited changes are still local on user’s machine but transcript of what happened is carried in the session’s logs.