After several months of testing Plakar across our infrastructure, I can confidently recommend this open-source backup tool. It efficiently handles everything from local files to multi-cloud AI pipelines while maintaining security and performance.
The Kloset engine underneath is the real differentiator. By packaging data with its context and metadata, Plakar extends beyond simple backups to support archiving, compliance logging, and dataset versioning - addressing multiple enterprise needs with a single solution.
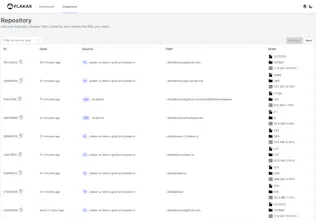
Cross-compatibility between environments has streamlined our operations, while the browsable UI saves valuable time during file retrieval. The cryptographically audited implementation gives us confidence in deploying it for sensitive data protection.
I particularly appreciate the efficient snapshot storage and instant recovery capabilities. For organizations seeking reliable data protection without unnecessary complexity, Plakar delivers.
The team behind this project includes former Veepee CTO, OpenBSD developers, and government tech lead - their expertise is evident in the solution's quality, even if they're too humble to mention it themselves.





Plakar
Hello everyone!
I’m Julien, co-founder of Plakar. Today, I’m thrilled to introduce Plakar, an open-source backup platform designed to meet the demands of modern workloads.
🔒 Why Plakar?
In an era where AI systems generate and process vast amounts of data, ensuring the integrity and security of that data is paramount. Plakar addresses this by providing:
• Immutable, encrypted backup: Ensuring data remains tamper-proof.
• Efficient storage: Unmatched deduplication and compression rate reduce storage needs.
• Queryable: Inspect backups with application context without full restores.
• Portable: Move backups across environments seamlessly.
💡 Built for Developers
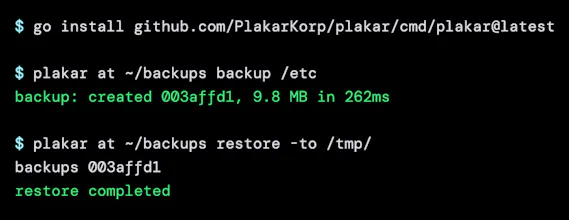
Plakar is designed with developers in mind, offering a CLI-first approach and seamless integration with various storage environments, including cloud-based storage, S3-compatible solutions, local servers, and Kubernetes volumes.
🔗 Get Started
Explore Plakar and see how it can simplify your backup and restore processes:
👉 plakar.io
We’re excited to hear your feedback and answer any questions.
Let’s make data protection effortless together!
I am impressed by your presentation video, but please make the font darker, sometimes it blends with your background and it is not clear what and how.
This sounds like a powerful solution for data integrity and backup management! I’m curious, how does Plakar handle incremental backups and ensure efficiency in large-scale environments with high-frequency data changes? Would love to know more about how it scales with big data workloads.
Plakar
@evgenii_zaitsev1
Thank you so much, really appreciate both the kind words and the honest feedback! We’ll definitely adjust the font contrast in the next cut of the demo, that’s super helpful to hear.
As for your question on incremental backups and scaling:
✅ Plakar is fully incremental by design.
We use a content-addressed snapshot model powered by our engine, Kloset, which means only the actual changes between snapshots are stored, both at file and block level. Snapshots reference existing content whenever possible, so storing thousands of restore points doesn’t mean thousands of copies.
✅ Scales both vertically and horizontally
Plakar is efficient on very large datasets, even with limited RAM, thanks to lazy indexing and deduplication.
It supports high-frequency backups without lock contention or index rebuilds.
Multiple backup sources (e.g., databases, cloud buckets, SaaS) can be unified in a single kloset, and backups can be pushed or pulled from different environments.
You can sync klosets across backends (e.g., S3 <-> local disk) and restore across storage types.
In short: you can back up frequently, keep a lot of history, and not explode your storage or memory budget.
We’d love to hear about your use case.
In our past experiences, we’ve had to deal with production environments under high load, where backups could easily become disruptive. That’s why Plakar was designed from the start to adapt its behavior based on system conditions.
For example, if a machine is under heavy I/O pressure, Plakar can automatically slow down its backup operations to avoid interfering with production workloads.
Looking ahead, we plan to improve this adaptive behavior with smarter algorithms, and even support external probes or metrics so you can define when Plakar should throttle or accelerate based on your own observability stack.
Our goal is simple: let you back up continuously without compromising performance or stability.
If you want to know more about Kloset, the immutable data store of Plakar, I encourage you to read this article: https://www.plakar.io/posts/2025-04-29/kloset-the-immutable-data-store/
This looks like a much-needed solution in today’s data-heavy world. Congrats on the launch! Is Plakar designed more for active backups of running systems or is it better suited for scheduled snapshot-style backups?
Plakar
@kay_arkain Thanks a lot!
Plakar is designed to support both use cases scheduled backups and active use in running systems.
Out of the box, it works great for snapshot-style backups, especially with its deduplication, retention handling, and low storage overhead (so you can run it more frequently than traditional tools).
But thanks to its architecture (no agent, lock-free operations, low memory usage), it’s also well-suited for frequent or even continuous backup workflows on active systems, including production environments.
We're also working on integrations to make this even easier to automate across diverse workloads (databases, cloud apps, hybrid storage).
In most cases, we’re able to create more restore points using less storage than many other setups.
Hey Plakar team!
It's definitely really nice what you guys have been building. I would love to have a conversation and learn more about the product.
Is there any way to get in touch with the team directly?
Strapi
Awesome to see months of hard work come to fruition with the first stable release of this open-source backup & restore platform, purpose-built for modern AI and cloud-native workloads.
I’m especially excited about Kloset, Plakar’s core engine, which does for data what Docker did for compute — making backups portable, verifiable, and instantly reusable across environments!
Plakar
disclaimer: I'm working for Plakar but I also use it for other projects in production
I’ve been using Plakar for a bit now. Before that, I had this whole setup with custom scripts to grab database dumps and sync my S3 buckets from my main provider to an external one. It worked… but it always felt a bit fragile, and I never fully trusted it.
With Plakar, things just work. I can search through my backups, preview files, and see the full history of everything stored in S3.
Backups aren’t something I have to worry about anymore — and that’s such a relief.
taatoo
I had a lot of problems with backups. Plakar could have been a really good alternative and less painful than other technologies.
I'll definitely try it in future projects !
Congrat's guys !
Plakar
@btor Thanks Thibaut! That’s exactly why we built Plakar backup shouldn’t be a mental burden or a constant source of doubt.
We want it to be something you can set up once, trust fully, and actually revisit without pain. Looking forward to hearing how it goes on your next projects! 👋