
ManyPI
Turn websites into APIs
489 followers
Turn websites into APIs
489 followers
Convert any website into a clean, type-safe API. Use natural-language or JSON-schema prompts to extract data and get usable JSON output for RAG pipelines, sales, content aggregation, or research.
Interactive
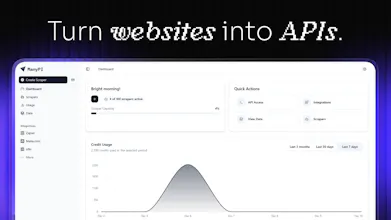
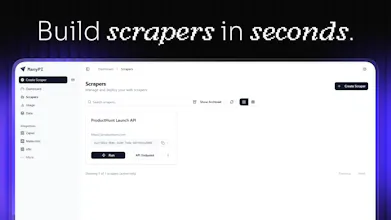

Free Options
Launch Team / Built With



Keupera
Hi folks,
ManyPI has just launched, and whether it’s praise, criticism, or suggestions for improvement: Share anything that comes to mind. Also, redeem code “PHBONUS” on the billing page to get 40k extra credits. Valid until Xmas. ;)
Best,
Ole
Really Nice. Very useful, and I like the fact it is user initiated, so it may not appear to websites as a bot. I like the clean interface too. How are you handling scraper blockers? And is my assumption correct that it doesn't appear as a bot to websites?
@tade_odunlami That is also what I'm worried about. if that leads to the account be banned, then it would be somewhat counterproductive.
Keupera
@tade_odunlami @joeyzhang We apply technical measures that reduce the likelihood of automated request detection while enabling controlled web data collection at scale.
Keupera
@tade_odunlami Thank you for your questions.
We have several technical measures in place to significantly reduce the likelihood of being flagged as a bot. These include fingerprinting, intelligent rate limiting, proxies, and additional safeguards.
So far, we are not aware of ManyPI ever being flagged as a bot by a website. That said, this does not mean it can never happen. We continuously work on keeping ManyPI’s stealth, integrity and reliability top-notch.
DeepTagger
Great idea! What are some of the top use-cases you've found? Also, how do you combat captchas?
Keupera
@avloss We’ve found ManyPI to be especially useful for researchers, RAG pipelines, and sales teams (e.g., for example, turning new Product Hunt launches into a structured API) - just to name a few. :)
Swytchcode
Amazing.
1. Where are the created APIs hosted or do you let them download it?
What if I need to edit my API manually or connect to db?
Which language is the API generated in?
Keupera
@chilarai
APIs and scraped data records are stored in EU data centers.
You can edit the API (name, website and JSON schema) by clicking the three dots in the bottom-right corner of the scraper card and selecting “Edit.”
If you need further customization, please let me know. I’d be happy to add it to the roadmap.
The API is JavaScript-based.
Wow, ManyPI is genius! The natural language prompting is seriously next level. How well does it handle websites with complex JavaScript rendering for scraping dynamic data?
Keupera
@jaydev13 ManyPI handles JavaScript rendering as well as pagination (e.g., load on scroll).
Feel free to give it a try. :)
Dead-simple API with reliable async polling and good support for JS-rendered pages. Integration was straightforward and fit cleanly into our existing pipeline.
How does ManyPI handle paywalled or authenticated content? Do users need first-party APIs or credentials for those platforms, or are only publicly delivered pages supported?
Overall, a solid tool.
Keupera
@popefhysx For now, in order to avoid unlawful use, ManyPI only supports pages that are public and not behind any auth- or paywalls. If this is a strongly needed feature, I can take it on the roadmap.
Keupera
@magrel Interesting idea. What do you have in mind? How do you imagine the use case? We’ve just released ManyPI Studio, Workflow, and Insights. For now, these are built on top of our API results—for example, transforming structured web data into charts via our new Data Studio. That said, I can definitely imagine supporting a more direct workflow in the future, such as turning entire websites into graphics, insights, and similar outputs.