
Launching today

Recall.OS
AI search for all your files. Nothing leaves your computer.
3 followers
AI search for all your files. Nothing leaves your computer.
3 followers
Most AI tools make you upload files to their servers and hope they answer correctly. Recall.OS flips everything: runs locally, auto-watches folders, and doesn't hallucinate because it's searching YOUR files not generating answers. Every response cites exact sources—page 12, timestamp 3:42, not "trust me bro." 25 documents free forever. Unlimited? $30 once, not $20/month forever. They own your data. You own the tool. First AI that treats your files like they're actually yours.


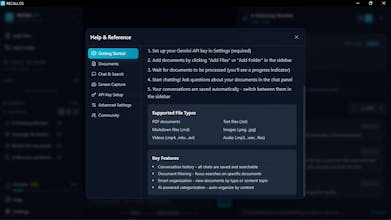




I built Recall.OS because I got tired of the cognitive dissonance.
The problem:
Every day I'd paste documents into ChatGPT because it genuinely helped me work faster. Then I'd close the window and think "I probably shouldn't have uploaded that." But I'd do it again the next day because the alternative was spending 20 minutes hunting through files manually.
We've all normalized this trade-off: convenience in exchange for handing over our documents to someone else's servers. It works until you actually stop and think about what you're giving away.
What I wanted to solve: Keep the utility. Kill the surveillance. Simple as that.
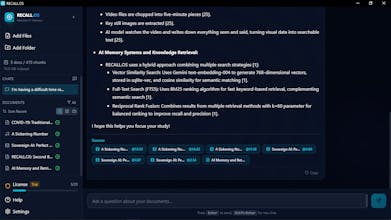
I wanted AI that could search through everything I have - PDFs, videos, screenshots, voice memos - and answer questions with actual proof, not hallucinations. But I wanted it to run on MY machine, with MY files staying local.
How it evolved:
Started as a simple PDF search tool. Then I realized people don't organize by file type - they organize by need. So I added video transcription, screenshot OCR, voice memo indexing. The goal became: just drop files anywhere, ask questions later.
The biggest challenge was citations. Other AI tools give you answers with no proof. I wanted every response to show me exactly where it found the information - page numbers, timestamps, source documents. That took longer to build than everything else combined, but it's the feature that makes this actually trustworthy.
What's here now:
Auto-indexing for PDFs, videos, audio, screenshots, documents
Q&A with source citations (page numbers, timestamps)
Runs locally - your files stay on your computer
25 documents free forever, unlimited for $30 once
What I'm still figuring out:
The API question. Right now it uses Google's Gemini API for processing questions. Only the questions and relevant snippets get sent, never full documents. But I know some people want 100% air-gapped. Working on a fully offline mode, but it's technically complex.
I'd genuinely love feedback on:
What file types would make this more useful for you?
Is the API approach a dealbreaker, or acceptable given the trade-offs?
What's missing that would make you actually use this daily?
This is the first piece of Project Intuitus - building AI tools that work for you, not on you. Thanks for checking it out.
Learn more: https://projectintuitus.com
Peerlist Launch: https://peerlist.io/projectintui...