
Yavy
Turn any website into an MCP server for AI
103 followers
Turn any website into an MCP server for AI
103 followers
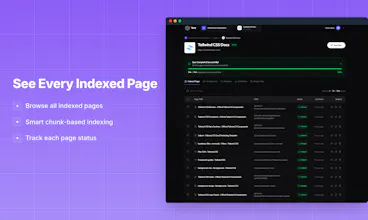
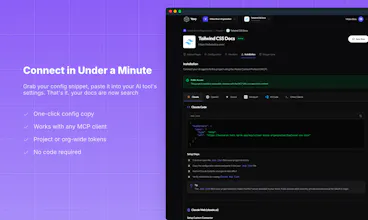
Yavy turns any public website into an MCP server. Paste a URL, and we crawl, index, and serve your content to AI tools like Claude, Cursor, and any MCP-compatible assistant. No more copy-pasting docs into chat. No more hallucinated answers. Your AI gets accurate, up-to-date information from your actual content. Perfect for developer docs, help centers, blogs, and knowledge bases. Set up in minutes - no code required. Organize multiple sources and share access with your team.



Free Options
Launch Team / Built With





Yavy
Easy Save AI
@vildanbina congratulations on the release
Yavy
@wealthyshezzy1 thanks a lot Yusuf
this is super cool, i've been dealing with mcp hell lately for my own startup and honestly the setup process is brutal. curious how you guys are handling the crawling and indexing - are you doing real-time updates when sites change or is it more of a snapshot thing? also wondering about rate limits and how you deal with sites that don't want to be crawled. we've been trying to connect our agents to docs and wikis and it's way harder than it should be, so really excited to see someone tackling this properly. congrats on the launch!
Yavy
@victor_eth really good question, regarding crawling, staleness-based snapshots, not real-time. Each page has a refresh frequency (daily by default). We only re-crawl what's actually stale and skip re-indexing if content hash hasn't changed. Regarding rate limits, 100ms delays between requests, max 5 concurrent jobs per project, depth/URL caps and we identify ourselves with a custom User-Agent. Regarding robots.txt, yes, we respect it. We check for Sitemap directives first and prefer using the site's own sitemap over recursive crawling
Would love to hear more about your use case!
ChatPal
Very cool! Will it automatically collect all sub directories content (e.g. from parent docs page, collect content of all docs)? This is huge pain manually
Yavy
The chunk-based indexing over full-page is a good decision — we've seen the same thing where full-page retrieval just drowns the context window with noise.
One thing I keep running into with MCP servers like this: once you're exposing content as tools, you eventually need to control who can call what. We're building keypost.ai for exactly that — policy enforcement at the MCP layer. Might be worth comparing notes.
Do you have plans for handling docs behind auth?
Yavy
@kxbnb thanks! the chunk-based approach was essential, we found 512-token chunks with 50-token overlap hit the sweet spot for retrieval quality.
For auth-protected docs, we currently support custom headers in the crawler config (API keys, bearer tokens). Full OAuth flows aren't there yet but it's on the roadmap, likely starting with Confluence/Notion API integrations since those are the most requested.
Interesting timing on keypost.ai - we've been thinking about multi-tenant access control as we see teams wanting to share doc servers. Would be curious to see how you handle policy definitions
i spend half my day feeding context to cursor manually. does it handle dynamic js-heavy sites well, or just static html?