
Sudo is a unified API for LLMs — the faster, cheaper way to route across OpenAI, Anthropic, Gemini, and more. One endpoint for lower latency, higher throughput, and lower costs than alternatives. Build smarter, scale faster, and do so with zero lock-in






Just poked around Sudo, love how it unifies model endpoints + handles billing & monetization in one layer. Makes stacking AI models feel way more seamless.
Amazing. Would be cool if you could also handle auto retries / rerouting to a different model so that there's extra latency saved on my server waiting to receive an error and then sending a new request to your API, instead I would describe retry policy and you implement it on your side. I haven't seen any of existing API's doing this but it would help massively for lower latency applications
Sudo AI
Hi @quasa0 that's a great idea, and we'll take it into consideration as a new feature to implement!
We currently have retry policies as a feature in our client SDK, but adding server-side retries to Sudo would make it easier for you, as the client, to never worry about receiving an AI response. You could define a fallback model or model provider, and if Sudo receives an error from the primary upstream provider, we could route you to your fallback model instead. This way, you, as the client, will experience less 502 errors and Sudo will have a higher uptime for you and your end-users.
Is that the idea you had in mind? Let me know if it would maybe be better to retry on the same primary model, in exchange for higher latency?
Is smart-routing (e.g. an "auto" mode where we pick the best model option for you) a feature you'd be interested in?
@0xphoenice yeah probably it's best if user can define the retry policy. For some people who value predictability having server side retries for the same model would work better. For some it's better to auto retry to a pre-defined model from another provider in order to avoid downtime in case a particular provider is having outages rn. I'm already doing this on client side but seems like could be useful to have on server side too.
Sudo AI
@quasa0 Great point, we'll add it to our notes! Some providers like Anthropic have outages and overloads, and I'm sure developers would want to switch to another model rather than wait for it to work.
We'll work on implementing that
Omi
Really interesting approach. I like that Sudo isn't just another router but is bundling in context + billing. Curious how smooth the developer experience feels in practice, will give it a try!!
Sudo AI
@josancamon19 Yup, we're bundling the whole AI developer experience into a single platform! Let us know if you have any feedback and how you find the DevEx to be. What are you planning on using Sudo to build?
Sudo is the unified API for LLMs, route across OpenAI, Anthropic, Gemini, and more with one endpoint. Lower latency, higher throughput, and reduced costs. Build smarter, scale faster, and stay free from lock-in.
Mom Clock
Congrats on the launch, Ventali! Does Sudo AI work like OpenRouter?
Sudo AI
@justin2025 Thanks Justin! Great question. In spirit, yes — Sudo is also a unified API for multiple models. The difference is that we provide faster routing on (DeepSeek, GPT-5-nano, o3, Grok-4-0709, Gemini-2.0-Flash, Claude-3.7-Sonnet, etc.) and we’re lower cost than alternatives (billing at cost + giving 10% bonus credits to early users).
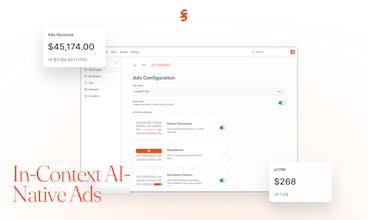
On top of that, we’re building vertical features for app developers — like context management at the app level (to make agents memory-aware) and in-context monetization (optional, policy-controlled ads) — all through a single API endpoint.
Curious: when you’ve used OpenRouter (or similar), what’s felt missing for your use case?
Congrats on the launch! 🚀 Developer stacks for AI are getting more complex, and Sudo AI is tackling real pain points. How does Sudo’s unified API optimize routing across providers like OpenAI, Anthropic, and Gemini, and what are the efficiency gains for latency, cost, or throughput? Can you share how the Context Management System enables stateful, memory-aware agents, and how real-time billing or AI-native ad monetization options work for app builders?
Sudo AI
Hi@sneh_shah! Our Rust-based backend and optimized server infrastructure ensures that we are competitive on latency and throughput with the best LLM routers on the market. Our benchmarks are open-sourced.
Our context management system (CMS) will be a feature that goes the extra mile that other AI developer platforms don't. Right now, LLM APIs don't have out-of-the-box features that let you connect knowledge bases to the agents and AI apps you build -- we are going to change that. Sudo will be the first LLM router with a managed Vector DB service, RAG for your agents and AI apps, memories via temporal knowledge graphs (tKG), and automatic context window optimization.
Real-time billing: billing end-users is a pain point that a lot of developers run into, especially in the landscape where model prices fluctuate so frequently. When we launch monetization for AI calls, Sudo will be able to bill your end-user for you, at your desired markup rate. All you'll have to do is authenticate your users with Sudo, with our provided SDK, and provide us with their user ID when you call the Sudo API. We'll charge their account, and you'll get paid. You never have to worry about changing model prices or integrating payment platforms again.
AI-Native Ads: Just like browsers and websites monetized traffic with ads, we believe the percolation of AI usage will drive costs down to zero as cost-sensitive customers demand free options, and AI provider companies burn through cash. Advertising will inevitably be a desired way to monetize a consumer-facing AI app or shopping agent, and we're 60% done building our own contextually-relevant product placement system for AI responses. In addition to that, we're experimenting with banner ads and other formats, all of which will be contextually relevant to the AI prompt and conversation. Developers will be able to simply toggle this option on, and get paid their publishing revenue.
CREAO
Congrats on the launch, Ventali! I’m curious about your context management system—could you share more details on how it actually works and how it handles memory or state for AI apps?
Sudo AI
Hi @chengka7! Great question! Sudo CMS is a model-agnostic context layer that assembles the right instructions + history + memory for each request:
CMS models context in three scopes:
Persona (long-lived user prefs, details, and facts)
Topic (project/space),
Conversation (chat thread).
On each request we assemble a prompt stack: convo history → topic notes → persona prefs. That gives your AI app stable memory (pinned facts), scoped recall (retrievable notes), and ephemeral state (chat history) — all deterministic, inspectable, and provider-agnostic.
So you don’t hand-roll memory plumbing — it’s built in. We do the RAG, Vector DB, knowledge graph, and file storage for you. You can just control it programmatically through our API.