Launched this week

PMB
Stop re-explaining your project to AI coding agents
293 followers
Stop re-explaining your project to AI coding agents
293 followers
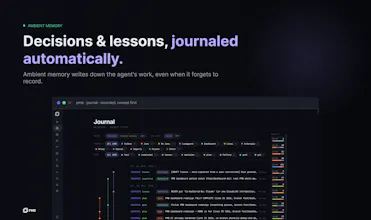
PMB gives Claude Code, Cursor, Codex and Zed persistent project memory through MCP. It stores decisions, lessons, goals, recent work, project facts and docs in one SQLite workspace on your disk. No cloud, no API keys, no LLM call on the read path. It is open source, offline-first, inspectable/exportable, with a local dashboard and honest impact tracking so you can see which memories actually help.











PMB
@shubham4real Thanks - and you've got the reasoning exactly right: the read path is pure local retrieval, so context costs you milliseconds, not an API call per interaction.
On conflicts: partially. For facts with a clean key it's resolved - latest-wins, old value archived. For two free-text decisions that contradict on the same part of the codebase, it's honest-partial today: both are stored as events, recency decay and relevance ranking push the newer one up, but there's no semantic detection that says "these two conflict" and hard-suppresses the stale one - so worst case both stay retrievable until one is corrected or archived. The hook for fixing it is already there, though: decisions about the same code cluster on the same entities in the graph, so detecting a conflict on a shared entity and flagging it for supersede/review is the next build.
Repo if you want to follow along: https://github.com/oleksiijko/pmb
the "no cloud, on your disk" call is the whole thing for me — local-first genuinely changes what people will put in their memory. building healthos on the same constraint. how's retrieval holding up as the graph grows into thousands of entities?
PMB
@sabber_ahamed Exactly. “Local-first” is not just a privacy feature here, it changes what users are willing to let the agent remember. For retrieval: it’s holding up well so far. My own PMB workspace is already at thousands of entities and tens of thousands of graph connections, and warm recall is still fast because SQLite stays the source of truth, while BM25 + vector search + graph expansion are used as retrieval/ranking layers. The biggest challenge has not been raw speed, but precision: making sure the agent gets the few memories that matter, not a huge context dump. So PMB is intentionally conservative about what it surfaces, especially for lessons/rules. HealthOS sounds like a perfect use case for the same constraint btw - health memory is exactly the kind of data people should not have to put in a cloud just to make it useful.
AISA AI Skills Test
this solves a real problem. the context re-explanation tax is probably the single biggest friction point in AI-assisted coding right now — you lose 10-15 minutes at the start of every session just getting the agent back up to speed on decisions you already made.
curious about the memory graph structure. how does it handle conflicting decisions? like if you stored "never use ORM" as a lesson but then later decided to add one for a specific service?
PMB
@ozandag That’s exactly the hard part: memory is only useful if it has scope and authority, not just storage.
PMB already does a few things here. Recall is not a flat keyword search: memories are ranked with multiple signals - lexical/vector match, importance, recency, graph/entity proximity, and follow-through history for lessons. The graph links decisions, lessons, files, projects, and entities, so a newer decision tied to a specific service/file can win in that context over a broader older rule.
So in your example, “never use ORM” would be treated as a general lesson. If later we store “use ORM for this billing service”, that newer and more specific decision should surface for billing-service work because of recency, entity scope, and graph relevance. The older lesson can still be useful elsewhere, but it should not have infinite authority.
The honest answer: PMB already has weighting, scoped recall, and conflict detection for factual state. The next step is making lifecycle explicit for decisions/lessons too - active / superseded / needs-review - and showing those conflicts in the dashboard instead of hiding them.
The goal is not “remember everything forever”. It’s memory with weight, scope, and aging.
Every new Claude Code session I spend the first few minutes re-explaining the same architecture decisions. The local-first + MCP approach is the right call, once project memory lives in a third-party cloud it becomes a security conversation for any serious team. The part I'd want most is the impact tracking that shows which memories actually influenced agent suggestions. Context without attribution is just noise. Look forward to hearing from you.
PMB
@frankgebuilder Exactly. The security boundary is a big part of why PMB is local-first: architecture decisions, mistakes, internal constraints, and “please never do this again” rules are exactly the kind of context teams do not want drifting into a third-party memory layer. And I completely agree on attribution. Memory should not just be injected silently and hoped for the best. PMB already tracks this for lessons: when a lesson is surfaced, it gets a surface_id; later agent actions can be linked back to that surface, and PMB tracks whether it was followed, ignored, or not applicable.
There is also an “Earned Memory” layer that connects surfaced lessons to outcomes like tests passing, builds, deploys, red-to-green fixes, and churn, so you can see which memories are actually pulling weight.
The next step is expanding that attribution beyond lessons into a fuller per-session influence trail for decisions, facts, goals, and project context. That’s the difference I want PMB to make: not just more context, but accountable context. If memory changes the agent’s behavior, you should be able to see why.
Love the local SQLite take. The staleness thing Dipankar raised kept biting me with Claude Code. Old assumptions resurfacing two refactors later, no way to tell whether the agent pulled them from memory or made them up. When a newer event reverses an older one without a clean key, does the dashboard surface "skipped because of X" or do I dig into events myself?
PMB
@yannikga That is exactly the failure mode I care about too: stale memory is worse than no memory if you cannot see where it came from.
Today PMB already gives attribution for the lesson path. When a lesson is surfaced, it gets a surface_id; later agent actions can be linked back to that surface, and PMB tracks whether it was followed, ignored, or not applicable. The Earned Memory layer then connects surfaced lessons to outcomes like tests passing, builds, deploys, red-to-green fixes, and churn.
For clean factual state, PMB also has validity/supersession mechanics: newer keyed facts can supersede older ones while keeping history and provenance.
The honest answer on your exact “newer event reverses an older one without a clean key” case: today, you can inspect the events and attribution trail, but the dashboard does not yet give a universal “skipped because of X” explanation for every memory type. That is the direction I want to take it: explicit active / superseded / needs-review states, plus a dashboard view that shows why a memory was used, skipped, or considered stale.
I agree with your framing: context without provenance is noise. PMB should make memory accountable, not just persistent.
Repo is here if you want to take a look or follow the work: https://github.com/oleksiijko/pmb
Mailwarm
How do you decide what gets written into memory, like is it automatic from chats or only explicit saves?
PMB
@karimbenkeroum Both. An ambient layer auto-captures the work product - decisions, lessons, corrections (correct the agent and it's saved as a high-priority lesson), completed work - deduped so nothing's stored twice. Explicit "remember this" is the override for pins, personal facts, or future plans. Default is you shouldn't have to tell it.
github.com/oleksiijko/pmb
So if I have a session in Claude, it will have the memory to store the chat from claude and when I switch to chatgpt or others llms it wil pick up the left over work from claude?
PMB
@mahir21 Yes, that’s exactly the idea, with one important nuance: PMB does not just dump the entire raw chat history into memory.
It stores the durable stuff that should survive between sessions: project decisions, lessons, bugs, goals, files touched, constraints, and “don’t do this again” rules.
So you can work in Claude Code, then later open Codex / Cursor / another MCP-aware agent connected to the same PMB workspace, and it can pick up the relevant context instead of starting from zero.
For plain ChatGPT, it depends on whether the client has a way to connect to PMB/MCP. But across MCP-compatible coding agents, yes - that is the workflow PMB is built for.