Launched this week

PMB
Stop re-explaining your project to AI coding agents
293 followers
Stop re-explaining your project to AI coding agents
293 followers
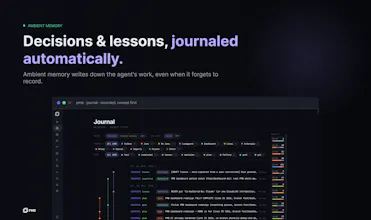
PMB gives Claude Code, Cursor, Codex and Zed persistent project memory through MCP. It stores decisions, lessons, goals, recent work, project facts and docs in one SQLite workspace on your disk. No cloud, no API keys, no LLM call on the read path. It is open source, offline-first, inspectable/exportable, with a local dashboard and honest impact tracking so you can see which memories actually help.











PMB’s local SQLite + no read-path LLM claim is the part I’d test first. The hard bit with project memory is not storing more facts; it’s deciding when an old fact should lose authority.
Do you track expiry or conflict per memory item? For example, if a repo switches from REST to GraphQL, I’d want the old REST decision preserved as history but not injected into a fresh coding-agent context unless the current file still touches that path. The dashboard would be more useful if it shows not just “this memory helped”, but “this memory was skipped because it conflicted with newer evidence.”
PMB
@tang_weigang Please do test it first - it's open source, so you can inspect the SQLite and confirm the read path makes zero network calls. And you've named the real problem: it's not storage, it's when a fact should lose authority. Today that's soft (recency + forgetting-curve decay) plus hard latest-wins for keyed facts, but there's no explicit per-item expiry or conflict flag for free-text decisions yet - so a REST decision after a GraphQL switch loses weight, but isn't hard-suppressed.
Both your ideas are spot on and going on the list: locality-scoped authority - injecting an old decision only if the current file still touches that path - maps directly onto PMB's code-entity graph (today it's emergent from ranking, not a hard gate); and the dashboard showing "skipped because it conflicted with newer evidence," not just "this memory helped," is the version that makes it auditable instead of trust-me.
Repo if you want to follow along: https://github.com/oleksiijko/pmb
The re-explaining loop between sessions is exactly what drives me nuts with Cursor and Claude Code, so local SQLite memory over MCP feels like the right call. How are you deciding what gets stored automatically vs what I have to tell it to remember? congrats on shipping.
PMB
@i_sanjay_gautam Thanks! And that loop is exactly what set me off too.
The split is roughly this: an ambient layer captures the work product automatically - decisions, lessons, corrections (when you correct the agent, that's stored as a high-priority lesson), and completed work - with dedup so the same thing isn't stored twice and secrets redacted on write. You don't have to narrate any of it. Explicit "remember this" is the override: things you want pinned, personal facts, or future intent the agent wouldn't infer from the work itself. Default is you shouldn't have to tell it - telling it is for emphasis or for what falls outside the work stream.
Repo if you want to follow along: https://github.com/oleksiijko/pmb
Curious how PMB handles context boundaries in practice — is it meant to store high-level project docs, repo-specific conventions, current tasks, or some mix of those?
PMB
@crystalmei It's intentionally a mix of all of those - the design goal is that you don't have to pre-sort it.
In practice: repo-specific conventions land as lessons ("we use X, never Y"), architectural direction as decisions, current work as goals/activity, and higher-level docs as reference/facts (it can ingest docs and PDFs too). Boundaries between projects are hard: each repo is its own workspace with a separate store, so conventions from one project can't bleed into another. Within a project, retrieval pulls the relevant blend for the task at hand - a convention plus a current goal plus the related decision - rather than dumping everything. So the boundary isn't something you draw by hand; workspaces wall off per repo, and relevance picks the slice per task.
Repo if you want to follow along: https://github.com/oleksiijko/pmb
This is exactly the problem that makes AI coding feel like a conversation reset every 5 minutes. You paste context, it forgets, you paste again. The local-first memory angle is smart - keeping it in the project rather than some cloud sync feels like the right call for sensitive codebases. Does it handle monorepos where different agents might need different context scopes?
PMB
@omri_ben_shoham1 Yeah, "conversation reset every 5 minutes" is exactly it.
Two ways today. For hard separation, a workspace isn't locked to a git repo - it's just an isolated store - so you can run one per package/app in the monorepo, and different agents pointing at different workspaces get genuinely different scopes that can't bleed into each other. For a single shared workspace, scoping is by relevance plus the code-entity graph: an agent working in package A surfaces memory tied to the paths and entities it's touching, not the whole monorepo. The fully airtight version - a hard locality gate so an agent only ever sees memory for the subtree it's in - is on the roadmap; today that scoping is emergent from ranking rather than enforced. No dedicated "monorepo mode" config yet, but those two primitives cover it in practice.
Repo if you want to follow along: https://github.com/oleksiijko/pmb
DiffSense
But remembering also has a cost. Your front loading context. aka using a lot of the available context before solving a problem. That means your runway to solve it is smaller. How do you get around that? some times you need all the context runway you have 😅
PMB
@conduit_design Ha, this is the sharpest version of the tradeoff - and you're right, remembering isn't free; it competes with the working window.
What keeps it cheap is that PMB is selective retrieval, not a dump. Recall is top-k and relevance-ranked (BM25 + vectors + graph), so what gets injected is a handful of items actually tied to the task - usually a few hundred tokens, not the whole store. prepare() at the start is a compact summary (counts, a few surfaced lessons, open goals), and recall() is pulled on demand mid-task rather than front-loading everything up front.
The other half: the baseline isn't an empty window, it's you re-pasting context every session or a fat always-on rules file that sits in context regardless of relevance. PMB swaps "always-on everything" for "on-demand relevant slice," so in practice it usually buys back more runway than it spends. And top-k is tunable - for a context-hungry task you keep the footprint minimal. There's still a nonzero floor, I won't pretend otherwise, but the whole design is "smallest slice that changes the answer," precisely because runway matters.
Repo if you want to follow along: https://github.com/oleksiijko/pmb
DiffSense
@oleksiijko Thanks for your answer. Any benchmarks for this? like head to head. Make a todo list app. with and without your smart memory mcp. And then run over 10 times or so against an agent not using PMB? and then viewing token use etc? and quality of delivery?
PMB
@conduit_design Exactly the right thing to ask for, and the right methodology - I'd rather show data than argue architecture.
Honest answer: I have one real head-to-head so far, not the repeated benchmark you're describing. On a small CLI build task, same agent with vs without PMB, measured from the agent's own token/turn telemetry: roughly 28% fewer tokens, ~31% less wall-clock, and fewer failed steps - mostly because the agent recalled the project's test command and conventions instead of re-deriving them by trial and error. Directionally strong, but it's n=1, so I won't dress it up as more than that.
What you're describing - one fixed task (a todo app is perfect), with/without PMB, N runs each, reporting tokens, turns and pass/fail plus a quality rubric - is exactly the benchmark that should exist, and the honest way to prove or kill the claim. I'm going to build it as a reproducible harness in the repo so anyone can run it, not just trust my screenshot. Token/time is easy to measure; the "quality of delivery" side is the harder part - that needs a fixed rubric or an LLM judge so it isn't me grading my own homework.
DiffSense
@oleksiijko really cool. Put it in a CI run. Run it every week as models improve etc. Then you have hard proof. also make a few different benchmarks maybe. some creative challanges. some more mechanical etc. That would be cool. And lead with that. people convert on outcomes. 5x faster 10x cheaper. reads better than. shared memory in all your tools etc. ✌️
Local-first memory for coding agents is interesting because context drift is usually where my sessions go sideways. I like that it avoids another hosted workspace. Curious how you handle stale project assumptions after a big refactor?
PMB
@xiaosong001 That’s exactly the tricky part. PMB should not treat memory as “true forever”.
Today recall is weighted by relevance, importance, recency, and graph/entity proximity, so newer memories tied to the files or services you’re touching can outrank older generic assumptions. For clean state-like facts, PMB also supports supersession/validity windows.
The next step is making this more explicit in the dashboard: active / superseded / needs-review states for project assumptions after big refactors.
Repo if you want to take a look or follow the work: https://github.com/oleksiijko/pmb
ModuleX
The local SQLite memory feels like the right call for keeping project context off the cloud, but I'm curious what stops an old decision you reversed two sessions ago from still surfacing as if it's current when the agent reads back?
PMB
@sezerufukyavuz That’s exactly the failure mode PMB is designed to avoid. Memory should not be treated as “true forever.”
PMB ranks recall by relevance, recency, importance, graph/entity proximity, and file/service scope, so a newer, more specific decision should outrank an older generic one. For state-like facts, PMB also has supersession/validity mechanics: the old value is kept as history, but no longer treated as current.
The next step is making this even more visible in the dashboard with explicit active / superseded / needs-review states for decisions and lessons.