Launching today

Agentmemory
Persistent memory for Claude Code, Codex & coding agents
326 followers
Persistent memory for Claude Code, Codex & coding agents
326 followers
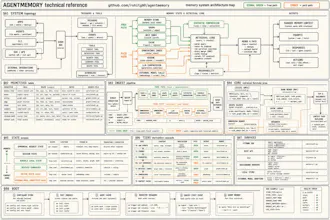
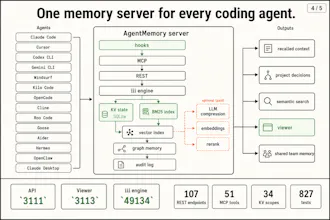
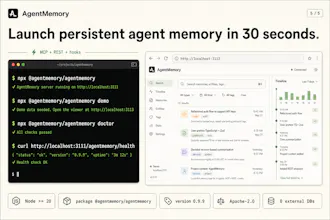
You can now give Hermes, Claude Code, and Codex infinite memory. Agentmemory is trending on GitHub with 5,000+ Stars. CLAUDE md dumps 22,000+ tokens into context at 240 observations agentmemory: 1,900 tokens. same observations. 92% less. At 1,000 observations, 80% of your built-in memories become invisible. agentmemory keeps 100% searchable. benchmarked on 240 real coding sessions → Up to 95% fewer tokens per session → 200x more tool calls before hitting context limits → 100% open source


Congrats on the launch.
2 questions:
Will this impact more usage on tokens? since the agent need looking around and search on newer chats?
Will the memory be persistent only in CLI agents or also on their desktop application as Codex, Claude, Cursor
Agentmemory
@rohit_ghumare that’s nice, what about 2#
Does it work only on CLIs?
92% token reduction is huge if it holds on real codebases. Curious how agentmemory handles conflicting observations: when newer context contradicts older stored memory, does recency win automatically or is there a manual override?
Cool project, how are you handling caching to ensure that it doesn't reprocess tokens unnecessarily in longer conversations?
Hey! Love it. How well would it help with handling pivots and knowing how my seed-stage startup's narrative/pitch deck and product spec changes over time? I've got canonical documents set up in Cursor, but it still takes a LOT of tidying work and any new scratch brainstorming files ruin the source of truth...
The context compression angle is genuinely interesting — 22k tokens down to 1.9k is a meaningful difference. Curious how it handles prioritisation when observations span very different task types (e.g. a debugging session vs. greenfield architecture work). Does it keep those namespaced, or blend into one pool?
The token reduction angle is useful, but the part I’d want to stress-test is retrieval quality over time. For coding agents, stale decisions and half-remembered debug notes can be worse than no memory unless there is a clear way to expire or scope observations per repo.
Congrats on the launch.
2 questions:
Will this impact more usage on tokens? since the agent need looking around and search on newer chats?
Will the memory be persistent only in CLI agents or also on their desktop application as Codex, Claude, Cursor