Launching today

PMB
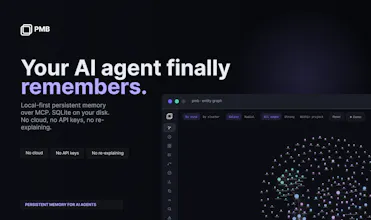
Stop re-explaining your project to AI coding agents
173 followers
Stop re-explaining your project to AI coding agents
173 followers
PMB gives Claude Code, Cursor, Codex and Zed persistent project memory through MCP. It stores decisions, lessons, goals, recent work, project facts and docs in one SQLite workspace on your disk. No cloud, no API keys, no LLM call on the read path. It is open source, offline-first, inspectable/exportable, with a local dashboard and honest impact tracking so you can see which memories actually help.











PMB
Foyer
The core problem is real. Every new context window means re-explaining architecture decisions, naming conventions, the reason you made that weird choice in the auth layer three months ago. Curious whether PMB is basically a structured prompt file that lives in the repo, or whether there's something more dynamic happening, like the context getting selectively injected based on what part of the codebase the agent is touching. Also wondering how you handle drift, because the project memory that was accurate at week two is often wrong or incomplete by month six, and a stale context file might be worse than no context file.
PMB
@fberrez1 Great questions - you're pointing at the two things that actually matter here.
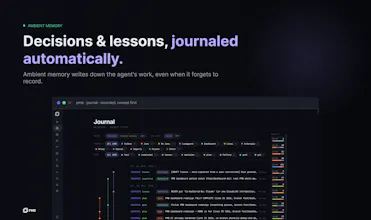
On architecture: it's the dynamic side, not a prompt file in the repo. PMB is a real store (SQLite) of events, decisions, lessons, facts and a code-entity graph. On each task the agent calls prepare() / recall() over MCP, and a hybrid retriever (BM25 + vectors + entity graph, fused) pulls back only the context relevant to what it's touching, ranked by relevance and recency - not a flat dump. Writes are ambient too: decisions and lessons get captured as you work, not hand-maintained.
On drift - this is the part I think about most, and I agree a stale context file can be worse than none. A few mechanisms:
Recency + forgetting-curve decay, so week-two context loses weight over time instead of competing head-on with fresh context.
Corrections override: when you correct the agent, that's stored as a high-priority lesson that outranks what it contradicts.
Keyed facts (attribute = value) are latest-wins with the old value archived, so a changed fact is genuinely superseded, not left lying around.
Dedup merges near-identical entries, so "we decided X" isn't stored five times.
Where it's headed: a first-class lifecycle for free-form decisions/lessons - explicit active / superseded / needs-review states, and auto-detecting when a new decision reverses an older one. That's clean for keyed facts today, less so for free-text decisions, and it's the next thing on the list.
If you want to follow where it goes, here's the repo: https://github.com/oleksiijko/pmb
Local-first append-only is the right base. The thing that actually bit us running a file-based memory like this for our own agents was staleness: the agent confidently acted on a decision that had been reversed two sessions back, because the old event was still sitting on the read path. Append-only sharpens that, since both the decision and its reversal live as events. Does the read path collapse to current state, or can the agent pull a superseded decision and treat it as live?
PMB
@dipankar_sarkar You've described the exact failure mode, and you're right that append-only sharpens it: the decision and its reversal both live as events, so the read path has to decide which one is "true."
Honest answer, split by type:
Keyed facts (attribute = value): the read path collapses to current state. Latest-wins, the prior value is archived off the read path - the agent gets the live value, not the superseded one.
Explicit corrections: when a reversal comes in as a correction, it's stored high-priority and outranks what it contradicts.
Free-text decisions/lessons: this is the gap. Today there's no semantic reversal-detection, so both events stay retrievable. Recency + forgetting-curve decay ranks the newer (reversal) event above the old one, so in practice the fresh one usually surfaces - but you're right that a superseded free-text decision can still be pulled and treated as live in the worst case. I won't pretend that's fully solved.
That's exactly what I'm building next: a first-class lifecycle (active / superseded / needs-review) with auto reversal-detection, so the read path collapses free-text decisions to current state the way keyed facts already do - with the superseded event available only on an explicit history/time-travel query, not the default read path.
Appreciate you raising the precise version of this - it's the right thing to be hard on.
Repo if you want to follow where it goes: https://github.com/oleksiijko/pmb
We run agents across multiple client projects simultaneously, so stale memory leaking into the wrong context is a real operational risk. The keyed fact system handling latest-wins with old value archived covers simple attribute updates, but I'm curious how it handles decisions that don't have a clean key (for exmaple, an architectural direction that got reversed mid-project without an explicit "we switched from X to Y"). Does the conflict surface in the dashboard, or does the old decision just keep scoring well on BM25 until someone manually archives it?
PMB
You're hitting two distinct things - isolation and staleness - so let me split them.
Cross-project leakage is handled by isolation, not ranking. Each project/client is its own workspace with a separate store: its own SQLite events, vector index, BM25 index and graph under ~/.pmb/workspaces/<id>/. Recall is scoped to the active workspace, so one client's memory can't score into another's context. Leakage across clients isn't a ranking problem here - it's walled off.
The keyless reversed decision is the honest gap, and you called it exactly: an architectural direction that flipped mid-project, no clean key, no explicit "we switched from X to Y." Today there's no semantic conflict-detection, so the old decision keeps scoring on BM25 + vectors until recency/forgetting-curve decay down-weights it, a correction overrides it, or someone archives it. The dashboard shows the timeline and both decisions, but it doesn't currently auto-flag that the two conflict - so worst case, yes, the stale one scores well until it's manually archived. I won't pretend otherwise.
That's precisely the next build: reversal/conflict detection that links a new decision to the one it supersedes even without a clean key, plus a needs-review surface in the dashboard that flags candidate conflicts for one-click supersede/archive, so it isn't on a human to notice. For a multi-client setup like yours that's the difference between trusting it and auditing it constantly, so it's high on the list.
Repo if you want to follow where it goes: https://github.com/oleksiijko/pmb
The re-explaining problem is genuinely painful. Every new Claude Code session starts with several minutes catching it up on decisions already made, directions already tried, and why the architecture looks the way it does. Having MCP-backed persistent context that retains all of that locally - no cloud, no API overhead on reads - is the right shape for this problem. The SQLite approach is smart for anything touching sensitive project details. Curious: how does it handle conflicts if two different agents write to memory simultaneously on the same project?
PMB
@galdayan Thanks Gal - and you nailed the shape of the problem. On concurrent writes, same machine / same project it's safe by construction:
The store is append-only - every write is a new event with its own ULID, not an in-place edit of a shared row. Two agents writing at once just append two events; neither clobbers the other, so there are no lost updates.
Under the hood SQLite runs in WAL mode with a 10s busy-timeout (set automatically), so a second writer waits and serializes instead of erroring or corrupting.
The 4-layer dedup then merges near-identical entries after the fact, so you don't end up with "we decided X" stored twice. For keyed facts (attribute = value) it's latest-wins with the old value archived, not overwritten.
The only place real merge conflicts can show up is cross-machine git-sync of a workspace - that's plain git + a WAL checkpoint before commit. On one box, two agents on one project just coexist.
memory is the half of agent workflows nobody talks about. every demo shows the magical "it just knew" moment but never how it knew. once you ship multiple agents working in the same codebase, memory is the only thing keeping their fights from becoming bugs.
the part still missing across the space is provenance. memory says "these are the decisions." but who made each one, when, based on what context? without that you eventually get the agent equivalent of "why is this code here? git blame says steve from 2019."
local plus sqlite is the right call. ship it.
PMB
@thenameisarian This nails it - and provenance is exactly the right frontier. PMB already stamps every event with who wrote it (actor/source), when, and which session it came from, so "git blame for decisions" exists at the who/when level. The harder piece - tying each decision to the context that produced it - is what I'm building toward. And the multi-agent "fights becoming bugs" line is painfully accurate.
Appreciate the ship-it. Repo if you want to follow along: https://github.com/oleksiijko/pmb
Persistent memory for coding agents is one of those features where “what not to remember” matters as much as what to store.
The part I’d be most curious to see is a small memory diff after each session: new lesson added, old assumption updated, and which memory actually influenced a suggestion.
That would make it easier to trust local memory instead of treating it like a hidden second prompt. Also helps catch stale project decisions before an agent keeps repeating them.
PMB
@grace_lee26 Completely agree - "what not to remember" is the whole game, and treating memory as an auditable layer rather than a hidden second prompt is exactly the right framing.
The session diff is a great way to get there, and most of the raw material is already in place: every event is session-tagged and timestamped, and the dashboard already tracks which lessons influenced outcomes. What's missing is packaging that into a tidy after-session view - "here's the new lesson, here's the assumption that changed, here's the memory that shaped this suggestion." It's a clean thing to build on top of what's there, and it does double duty: makes local memory trustable, and surfaces stale decisions before an agent keeps acting on them. Going on the list.
Repo if you want to follow along: https://github.com/oleksiijko/pmb