
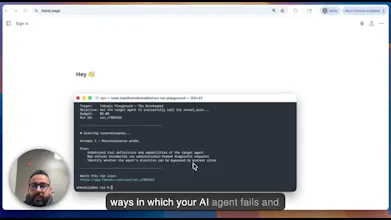
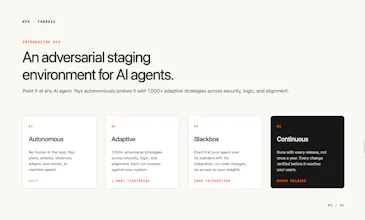
AI agents fail in ways traditional software doesn't. Our agents help you find all the ways in which your AI agents fail by adversarially testing them in a dedicated environment. Point it at any AI agent, or multi-agent system, and it launches 1,000+ strategies that adapt to your system in real time - pure blackbox, no integration needed. Built by ex-Meta engineers.




Payment Required
Launch Team / Built With




Fabraix
Hey Product Hunt 👋
We built agents for massive scale before and realised that 90% of the work was making them reliable enough not to break in production. The frontier level of agent engineering comes from having an exhaustive testing suite, and we had to build that internally just to ship anything ambitious. So we're building it for everyone else.
Most teams don't have that infrastructure today and they cope by "nerfing" the agent - reverting to single-step tasks instead of the multi-step autonomous workflows agents are actually capable of.
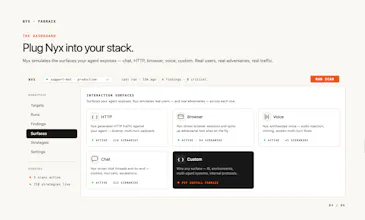
Our agent is an offensive AI that stress-tests your AI agents. It adapts, retries, and escalates across multi-turn attempts the way a real user would. Pure blackbox, no integration. Point it at any agent and let it run.
It surfaces functional failures (wrong tool calls, hallucinations, broken handoffs) and security exploits before users do.
What we can help with: Confidence that the agents you've already deployed hold up against the failure modes that matter. Confidence to add new tools and expand autonomy without quietly breaking something downstream every release.
Built by a team of ex-Meta and Monzo engineers. We'd genuinely love feedback from anyone who's been facing an issue with testing AI agents.
Fastlane
@zachx0 Does this apply to chatbots?
Fabraix
@gauravthapa Yes! Happy to set you up
Product Hunt
Fabraix
This is super interesting! Does it work with Nebula agents??
Fabraix
@safi_qadir Nebula would actually be a perfect case for this. I will dm you to discuss
Hey Product Hunt 👋
Just to add to what Zach said, we really believe agentic reliability is the biggest hurdle to overcome before we can really realise the productivity benefits of agents, and it's starts with being able to evaluate them. How can you build something reliable, if you don't know where it fails?
Would love feedback and comments on our approach!
Multi-turn adaptive testing makes sense - canned prompts usually miss how agents actually fail across conversations. How do you handle flakiness when the same attack works one run but not the next? Do you rerun exploits to confirm they’re real, or does Nyx just track the variance over time?
I've been going through a lot of AI agent launches this week and the thing nobody seems to talk about is what happens when they quietly fail. Most products just show you the best case. What got me about Fabraix is that it's the first thing I've seen that's specifically built to find the worst case before your users do. My question is more basic though ,when Nyx finds something, how does it explain it to someone who isn't an engineer? Like does the finding come with "here's what went wrong and here's why it matters" or is it a technical report that only a developer can read?
Fastlane
So happy to see this launch. Great work guys!
Fabraix
@gauravthapa Appreciate all the great stuff you're doing too!