Found MartinLoop through a thread on Hacker News where someone was venting about a Claude Code run that estimated $2.40 and ended up burning $65 in retries before they noticed. Felt that pain personally so I clicked through and gave it a try. Spent the last 2 weeks running it as a wrapper around my Codex and Claude Code workflows for a side project. The whole "give the agent a finish line" concept clicks immediately when you've ever watched an agent loop on itself overnight.
The killer features for me are the hard budget caps and the verifier gates. You set a dollar limit before the run, point it at your test suite (like npm test), and the agent stops when it hits either the budget or a clean verifier pass. No more "wake up to a $300 OpenAI bill because the agent kept retrying a typo." The JSONL run records are also surprisingly useful when something does go sideways. You get a clean receipt of what changed, what passed, what failed, and exactly where the spend went.
Where it gets rough: setup is CLI-only right now, no hosted dashboard yet (it's on the waitlist for Pro tier). Side effects that escape the repo boundary, like DB migrations or external API calls, still need manual fencing through safety policy. Not a deal breaker but you do need to think about scope upfront. Apache 2.0 license and npm install -g martin-loop to get started means there's zero friction to try it. For anyone running coding agents in production or even just for side projects, this fixes a real problem that nobody else is addressing seriously




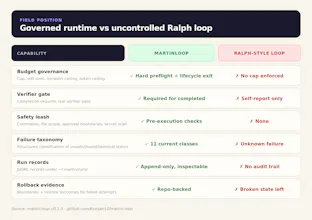







Useful framing. The part I would want before trusting a long-running agent is a concise run receipt: budget spent, verifier failures, scope guard hits, and the exact stop reason. If you surface that per run, it becomes much easier to compare agents without rereading logs.
The verifier gated admission rule is the part that separates this from a spend cap with a nicer dashboard. Capping tokens is easy. Refusing the next attempt until something actually changed is the rule that kills the “busy” loops. Where I would push: rollback evidence and a JSONL trail are clean when the only artifact is a file diff, but a real coding run also fires migrations, seeds data, and calls external APIs that git cannot undo. How does MartinLoop treat side effects that escape the repo boundary? Does the safety policy let me declare which actions are irreversible so the gate refuses to even attempt them unattended, or is fencing those off still on the operator?
@zimasilevuyo
That’s exactly the right push. Git rollback is only half the story.
The real danger is everything that escapes the repo: migrations, writes to external services, secrets use, emails, payments, queue publishes.
Our view is that those need to be declared up front as action classes, not discovered after the fact. Then the runtime can do three things: block some classes entirely when unattended, require explicit approval for others, and leave a receipt for the ones it does allow so you can reconstruct what happened later.
So no, I would not treat repo rollback as enough. The safety layer has to know which side effects are reversible, which are recoverable, and which are simply too risky to run on autopilot.
Good work! Are JSONL records capturing rejected paths or only the committed one?
One thing I would genuinely love feedback on from launch-day testers: what proof would you want before trusting a coding agent overnight? Budget receipt, verifier result, rollback path, or a file-level diff trail? MartinLoop is built around making those runs inspectable instead of just fast.
Good question. The useful receipt should show both the committed path and the rejected ones. If you only keep the final successful branch, you lose the story of why the run got expensive or risky. The operator should be able to see which paths were blocked, which verifier failed, and why the next attempt was or was not admitted.
One lesson from testing coding agents: cost usually spikes after the first failure, not before it. If the agent can't show a receipt for done, the next retry should get harder, not easier: cap the spend, require a verifier check, and stop when the same mistake repeats. If you've seen a failure mode we should test before launch, I'd love that feedback.
A small rule that catches a lot of fake progress: if the agent can't explain what changed since the last attempt in one sentence, it probably should not get another retry yet. That sounds strict, but it saves a lot of budget from "busy" loops that only reshuffle the same failure.