
Ultramemory
Private AI memory for your Mac with no cloud or account
86 followers
Private AI memory for your Mac with no cloud or account
86 followers
Ultramemory turns your email, Slack, files, and screenshots into a private memory on your Mac — making everything searchable and answers your questions with citations you can check. Free, open source, fully local.
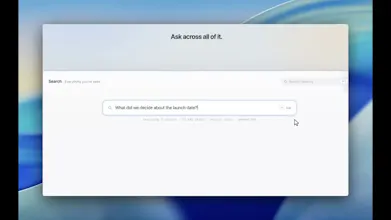





Ultramemory
memi
Fully local memory with citations is exactly the right trust posture. I’d use this less as “AI remembers everything” and more as “I can verify where every answer came from.” How are you ranking sources across files, Slack, email, and screenshots?
Ultramemory
@sarveshsea I don't actually rank the sources against each other. Files, email, Slack,
and screenshots (those get OCR'd to text first) all normalize into the same
chunk format, so an email and a screenshot compete on the same footing.
Retrieval runs two ways in parallel: BM25 keyword search and embedding/vector
search. I fuse the two ranked lists with reciprocal rank fusion, then a scoring
pass weights each candidate by how important it looked when it was indexed,
recency (slow decay, so things from months back still surface), and intent.
Intent is where source type re-enters: if the query reads like a calendar
question, events get boosted; if you say "the email from Sarah," Gmail from
that sender jumps. So sources aren't ranked in a fixed order, the question
reweights them.
And yeah, verify-where-it-came-from is the whole point for me. Every answer is
assembled from those top chunks and links straight back to the original
file/email/message.
no cloud + no account is the right default here. the part that bites is retrieval staying fast as the local store grows past months of history — no-account makes that harder, not easier.
Ultramemory
@qifengzheng Agreed, that's the constraint I watch most. Why it holds up locally though:
The keyword side is SQLite FTS5 (BM25), which stays fast into the millions of
rows. The vector side is brute-force KNN over sqlite-vec right now, which is
the honest weak point. At one-person scale (tens of thousands of chunks, not a
web corpus) it's still far quicker than the local model takes to write the
answer, so search isn't the bottleneck yet. If someone loads in years of dense
Slack and email, that's where I'd drop in a real ANN index. I'd rather ship the
simple version and add that when the data demands it than build for scale I
don't have.
On no-account making it harder: retrieval is on-device either way, so an account
wouldn't speed up local search, it'd just add a server I don't want to run. What
keeps it fast is the index design, not where auth lives. Recency weighting helps
too, the set that actually matters stays bounded even as raw history piles up.
@jared_goeringbrute-force knn over sqlite-vec is the right call early — linear scan beats index overhead until the vectors pile up. the hard part is finding the crossover point before recall or latency starts to hurt.