Launched this week
Revolte
AI for Software Engineering
388 followers
AI for Software Engineering
388 followers
Revolte is for engineering teams to turn intent into production-ready software faster, safer, and with more control. Its agents plan changes, generate code, run quality and security checks, create PRs, support deployment, monitor runtime behavior, and surface risks early. Engineers approve the important decisions. Revolte handles the delivery heavy lifting. Built for higher delivery throughput across SDLC, stronger governance, and more value shipped per engineer.
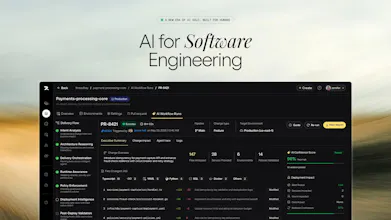





Free Options
Launch Team / Built With




AI for software engineering is one of the categories where the demo always looks great and the daily use breaks at the edges — codebase context, multi-file refactors, and stale dependencies. Curious how Revolte handles the case where the codebase convention contradicts what the model has seen most in training. I run into the same problem on the financial-modeling side — my channel Mod3Loop covers a lot of this kind of edge-case behavior in modeling tools that mostly work until they suddenly do not.
@samir_asadov That is exactly the edge case we care about. The model’s default instinct is often to follow the most common pattern it has seen, but real production codebases usually have their own conventions, older layers, exceptions, and sometimes strange but intentional trade-offs.
Our approach is to make the local codebase context the source of truth. Revolte first looks at the existing patterns around the change area: similar files, service boundaries, naming conventions, dependency usage, test structure, PR history, and project-specific instructions. The agent is then guided to work within those conventions instead of applying a generic “best practice” from training.
We also do not treat generation as the final step. The value is in the loop around it: implementation, tests, checks, review, and human approval where there is ambiguity. That is especially important when the codebase convention and the model’s default answer do not match.
Your financial-modeling analogy is a good one. Most tools work well in the clean path but the real product test is what happens at the edges.
Revolte
@samir_asadov
Really appreciate the question — and the Mod3Loop reference lands well, it’s exactly that “mostly works until it doesn’t” failure mode we’ve spent a lot of time thinking about.
The short answer is context wins over training. Revolte builds a dedicated context layer per App or Service that captures the specific conventions, patterns, and structure of that codebase. When agents run, they work from that context — not from generic assumptions baked in during model training. So if your codebase does something unconventional, the agent follows your convention, not what it’s seen most.
That’s also why we’re deliberate about how context is built — it’s not just file ingestion, it’s structured context that actually reflects how that specific codebase operates. The more accurately the context represents the repo, the less the model’s prior training interferes.
It’s never a fully solved problem — edge cases exist — but the human approval layer means those edge cases get caught before they cause damage.
@imtiaj_ahmad Very fair question. This is exactly where most AI dev tools struggle.
Our approach is not to throw the whole legacy repo at an agent and expect magic. Revolte keeps the scope bounded around the actual change: relevant files, existing patterns, service boundaries, test paths, PR history, and project-specific instructions.
Messier codebases need more context and more control, not more blind autonomy. The value is in helping the agent know what to touch, what not to touch, what to test, and where a human should review before it moves forward.
Revolte
@imtiaj_ahmad We've heard this one a lot — and it's a fair scepticism to have.
Here's what we've found: the age of the codebase isn't actually the problem. Revolte builds a dedicated context layer per App or Service, and once that context is solid, the agents work just as effectively on a 10 year old repo as a brand new one.
The harder cases are codebases that are poorly documented or structurally inconsistent — not because Revolte can't handle them, but because no tool can reason well about something that isn't well defined. So we work with teams upfront to map out the service structure and fill the context gaps before workflows kick off.
Think of it like onboarding a new senior engineer — you wouldn't throw them at a legacy codebase with zero documentation and expect magic. Give them the right context and they'll figure it out. Revolte works the same way.
This feels like Cursor meets Jarvis 👀 How accurate is the task execution in real world coding workflows?
@nithin_raju1 Good question and an important distinction — task execution accuracy is really asking whether the agent actually completes the job end to end, or gets lost halfway through.
The honest answer is that the pipeline structure is what makes execution reliable in practice. There's a planner step that runs before any code gets written — it maps out what the task actually involves and what done looks like. That upfront planning step is what prevents the agent from going off in the wrong direction and only discovering it three commits later.
From there each step in the pipeline — codegen, testgen, regression — has a defined scope and exit condition. It's not one agent trying to freestyle the whole thing. And if something fails at any stage, it surfaces there rather than quietly producing something broken that reaches a PR.
Where execution gets harder is with tasks that span multiple services or involve calls that need real domain judgment — those are the ones where we've deliberately kept humans in the loop rather than pushing for full automation. The goal isn't maximum autonomy, it's reliable execution on the work that can run cleanly, and a clear handoff when it can't.
What we're seeing with customers is that the volume of tasks completing end to end without constant intervention has gone up significantly. That's the real signal on execution for us.
Congrats on the launch team! Quick question though: how is this actually different from Cursor or Claude Code? Trying to figure out where Revolte fits in my stack.
Revolte
@keerthana07 totally fair question, and honestly the one we get most! 💪
Cursor and Claude Code are brilliant tools, but they're essentially a smarter pair of hands for the developer. You're still driving, still prompting, still context-switching between coding and everything else.
Revolte works at a different level. It's not just helping you code, it's handling the whole delivery cycle autonomously: planning, coding, test generation, security scanning, PR creation, all running as one connected workflow with no one babysitting each step.
The dev or tester comes in at the end, opens Revolte Code, reviews what the agents produced, makes any edits, and approves. That's the moment of human judgement, not the hours of groundwork before it.
So in your stack: Cursor and Claude Code assist the developer writing code. Revolte assists the entire delivery process, from ticket to merged PR, with specialised agent personas for development, automation testing, non-functional testing, bug fixing and more.
If Cursor is a smart co-pilot, Revolte is the autonomous crew. ❤️🔥
@rajagopalanar Thanks for your answer. This further deepens my question.
This makes complete sense for greenfield delivery, when I have no ecosystem in place. But how does it suit for existing environments where I already have CI/CD Pipelines, QA workflows, Jira processes etc ?
In my opinion, most companies / dev team managers may not be ready to replace their stack entirely, and this is where claude code or cursor works for them: in the small window of "developer-only productivity".
Curious on how Revolte sits here, will it be another platform the wider engineering team has to adapt to.
Revolte
@keerthana07 this is the follow-up I was hoping for, you've hit the exact concern that decides whether something like Revolte lands in a real team or stays a demo. 💪
Honest answer: Revolte isn't replacing your stack, it plugs into it. CI/CD, Jira, QA workflows, Git, security tools, all stay. Revolte is the autonomous layer driving work through them: planning agent reads from Jira, coding agent respects your branch and PR conventions, tests run in your existing pipeline.
So the wider team isn't adopting a heavy new platform. Devs review PRs where they always have. The groundwork just arrives pre-done with full context, instead of starting from a blank ticket.
And you're right that Cursor and Claude Code shine in the developer-only window, that doesn't go away. Plenty of our users run both. Revolte just solves for the team and the delivery cycle, not the individual at the keyboard
"AI for software engineering" could be five different products, so I honestly can't tell what this is yet. A code editor? An agent that opens PRs? A Copilot-style layer with more context? What does one normal task look like start to finish, and what happens when the repo has no tests and no spec to work from? That's the case that breaks most of these for me.
But I'm also glad you exist guys, I'm just here to challenge you haha
Congrats for the launch
Revolte
@fberrez1 this is exactly the comment I was hoping someone would write, so thank you for grilling it. 💪
Fair point that "AI for software engineering" could mean five things, so to be specific: Revolte is an autonomous agentic platform for the whole SDLC. You define a workflow — planning, coding, test generation, SAST, DAST, bug fixing, PR creation — and the agents run it end to end, no human babysitting every step.
One normal task: a feature gets requested → planning agent breaks it down → coding agent implements → tests generate automatically → security scans run → a PR is raised. You open Revolte, review, tweak, approve. Done.
And the no-tests, no-spec case is exactly where Revolte earns its keep, because that's what breaks most tools. No spec? The planning agent builds one. No tests? The test agent writes them in the same flow. You come in at the end to approve, not to hand-hold.
So please keep challenging us, this is the good stuff. And congrats right back for asking the real question. ❤️🔥
@rajagopalanar What stands out about Revolte isn't just the AI assistance, but it's the philosophy. Tools should amplify human judgment, not override it.
As someone who writes about practical tech at Your Tech Compass, I see too many "AI fixes everything" promises that skip the nuance. Revolte feels different: the iterative suggestion flow (try-tweak-approve) mirrors how thoughtful devs actually work.
One thing I'm curious about as I test: can teams customize Revolte's "confidence threshold" for auto-suggestions? For example, "only suggest changes with >90% confidence" vs. "show me everything and let me filter." Asking because for risk-averse teams (and readers who value transparency), that control knob could be the difference between "cool demo" and "daily driver."
Congrats on launching something that feels both powerful and humane.
Diana - Your Tech Compass
Revolte
@diana_nadim2 Thanks for the comments. Absolutely. We dont see Revolte to be one another AI assistant tool that helps developer. We wanted to drive outputs which could be autonomously driven by AI workflows.
Once the AI has completed the output with its own predicted confident score, human in the loop - Developer or tester will review and approve the output. Based on the approval ratio, the confident score will be adjusted on each run while Agents takes measured feedback from previous review to self improve to maintain the confident score.
We call it right mix of AI and human to bring in 8x productivity and 10X release acceleration.
How is security checking implemented? Do you have internal rules or checklists?
Revolte
@natalia_iankovych
Great question — security is something we’ve been deliberate about on two fronts.
On the code side, Revolte has dedicated SAST and DAST workflow templates built in. So security scanning isn’t a manual step someone remembers to add — it’s part of the workflow by default. Static analysis catches issues in the code itself, dynamic testing covers runtime behaviour. Both run as part of the same autonomous pipeline before anything reaches a PR.
On the platform side, we’ve been equally careful about how the agents themselves operate. Every agent and workflow has clearly defined boundaries and access controls — they can only touch what they’re supposed to touch. This wasn’t an afterthought; giving autonomous agents broad access across a codebase without guardrails is how things go wrong fast.
So the short answer: code security is handled through SAST/DAST templates, and agent security is handled through strict access definitions baked into how Revolte is structured.