
Launched this week
OpenBug
Ticket in, fix out. Every solution trains the next one.
75 followers
Ticket in, fix out. Every solution trains the next one.
75 followers
OpenBug is an open-source CLI that turns bug tickets into fixes. Paste a ticket, and the AI agent investigates your logs, reads your code, correlates across services, and delivers a diff. Every fix adds to a shared runbook in git — so your team gets smarter with every bug solved.




Essays by Paul Graham GPT
Hey Product Hunt! 👋
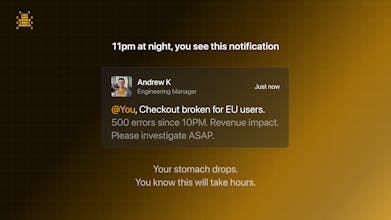
We built OpenBug because we were tired of the same debugging loop: vague ticket comes in, you spend 2 hours reproducing it, grep through logs, read 15 files, fix it, and then the knowledge just… disappears.
Next month, a teammate hits the same class of bug and starts from zero.
OpenBug fixes that loop. It's an open-source CLI and a GUI where you:
1 → Paste a bug ticket (or just describe the problem)
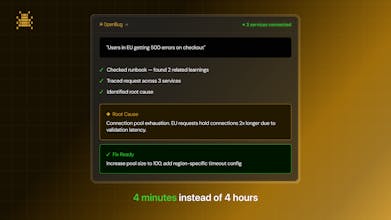
2 → The AI agent investigates — reads your logs, inspects your code, traces across microservices
3 → You get a code diff with the fix
4 →The solution gets saved to a runbook in git
The whole thing runs in your terminal. No SDK to install, no config files to write.
and prefix your commands with debug.
It's fully open-source (MIT) on GitHub.
Would love your feedback, what would make this useful for your team?
self-improving bug fixes is wild. every ticket making the system smarter is how AI should work
Essays by Paul Graham GPT
@cogotemartinez
Yeah this was one of the main things that frustrated us with existing tools - every bug is treated like a blank slate. The runbook is just a markdown file checked into git. When the agent investigates a new issue, it pulls from past resolutions in that file. No fancy RAG pipeline, just accumulated context that grows with each fix. Compounds pretty quickly.
Starnus
Very nice! Handling bugs are always the most energy consuming part of coding
Curious to know how do you see the difference with Cursor's Debugging mode or Claude Code or similar coding tools?
Essays by Paul Graham GPT
@khashayar_mansourizadeh1 Good question Khashayar! Cursor and Claude Code are great when you're already in the codebase and know where the bug is - you need help writing the fix.
OpenBug works one step earlier. You have a vague ticket like "EU users getting 500 errors on checkout" and don't know where to start. It connects to your running services, reads logs, traces the issue across service boundaries, and gives you the diff.
The other difference is the runbook - the system picks up learnings from each investigation and saves them. Cursor doesn't remember your team hit a similar connection pool issue three weeks ago.
They're honestly complementary. OpenBug to investigate and get the fix, Cursor/Claude Code if you want to take the implementation further.
Essays by Paul Graham GPT
@yerbolat Thank you :D
Right now OpenBug is focused on the CLI and the debugging loop itself. You connect it to your running services (any language, any framework, just prefix the command with debug) and it works with your logs and codebase directly.
The runbook saves as a markdown file in your repo, so it flows through whatever git workflow you already use. Integrations are on the roadmap - what would be most useful for your setup?
The self-learning aspect is what makes this interesting — each resolution making the system smarter over time. For open source projects, this could be a huge time saver. What's the learning curve like for the first few hundred tickets?
Convo
@tugay_pala Haven't benchmarked it for open source products. That's a great idea though! I can backtest it on a specific project and measure the delta. Will do.
Essays by Paul Graham GPT
@tugay_pala The learning curve is basically flat for getting started.
then
and you're in. Ask it a question about whatever just broke.
For the runbook side, it's more of a slow build than a curve. The first few tickets, the AI is working mostly from your logs and code. By ticket 20-30, the runbook has enough entries that you start seeing it reference past investigations. "This looks similar to the pool exhaustion issue from last week" kind of thing.
Over time it also builds an understanding of the project itself, so the agent should be able to start reproducing issues on its own.
For open source projects specifically, the interesting part is that the runbook lives in the repo. So contributors who've never seen the codebase before get the benefit of debugging knowledge from people who have.