
Jupid
File your taxes with Claude Code
1.1K followers
File your taxes with Claude Code
1.1K followers
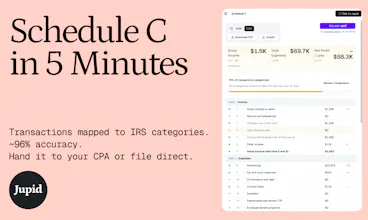
No matter how powerful LLMs get, they are objectively bad at financial transactions. Context loss, inconsistent categories, no memory between sessions. Jupid fixes the data layer. Connect your bank — it learns your business and every vendor relationship once, then remembers forever. Transactions mapped to IRS Schedule C categories (~96% accuracy). Missed deductions found: $1,249/year average. File your Schedule C in 5 minutes. Works with Claude Code. Free trial + 50% off first 3 months.









Love this!!!! Can I connect this to e.g., Zenvoice? So I do not have to sit in between the transactions and my accountant?
@wouter_rocchi Wouter, thank you! Yes, that's exactly the vision — you shouldn't have to sit in between your transactions and your accountant. Right now we integrate with QuickBooks, and we're building more integrations. The idea is that Jupid handles all the categorization and enrichment automatically, and your accountant gets clean, ready-to-use data. No more back-and-forth spreadsheets.
@slavaakulov Nice! I think in NL a lot of smaller businesses and accountants are using zenvoices. Could be worth considering if you are planning a serious market entry here.
@wouter_rocchi Yes, we’re in NL. I know a lot of smaller businesses and accountants there use Zenvoice. Thanks for the pointer — we’ll definitely take a look and maybe come up with something around that.
HasData
Curious how the onboarding feels when you have zero history. Does Jupid ask a bunch of questions upfront or just figures things out as transactions come in?
@ermakovich_sergey Great question! We've minimized onboarding questions as much as possible. Instead, we use your online presence to gather information about your company, your operations, revenue streams, whether you have offices, and so on. We build your profile from external sources before we even ask you anything.
Same approach with transactions — we gather background on most counterparties automatically. Anything that's still unclear, we ask about gradually over time, so by the end of the year you have a filing-ready context without ever sitting through a painful onboarding session
You say 'raw bank data never touches AI providers.' Can you be more specific? What exactly does the AI see vs. what stays private?
@wiltodelta To be more specific: we do not send raw bank transactions to AI providers. What we do is enrich counterparties using publicly available data based on the merchant information, without sending private details anywhere. We do not pass names, surnames, home addresses, or anything like that. The model works with your business profile and the counterparty context, not with your raw banking feed.
Lovon AI therapy
Great product! But how does the bank connection work? Is it Plaid? And what happens if my bank isn't supported?
@thxgrey Yes, we work through Plaid. If Plaid isn’t available for your bank, we’ll soon have another integration as well. Also, Plaid supports a lot of banks and payment systems, and any spreadsheet or CSV already works with.
@ivan_borisov3 Yes, this is exactly the kind of problem we built for.
We do not just look at `PAYPAL *TRANSFER` and stop there. If it is a real transfer, it is usually just money moving between your own accounts. But most PayPal transactions still give you a merchant clue somewhere.
We take that merchant, enrich it, build context around the counterparty, and work from there. Otherwise the model just starts guessing and the categories drift.
How do you ensure deterministic results when Claude is handling actual tax calculations, is there a verification layer that catches hallucinated numbers before filing? Really bold product idea!
@borrellr_ Great question. We do not let Claude freestyle on raw bank data and then hope the numbers are right.
First we structure the transactions, build context, map everything properly, and only then let the model work on top of that. So the filing layer is not "Claude guessed it" - there is a human verification and rules layer before anything goes into filing.
Spiritme
What about using an LLM with a vector database for persistent context? Seems like that would solve the memory problem without a new product.
@nikita_bogdanov1 Great technical question. Vector search helps with recall but doesn't solve the categorization consistency problem. You need structured vendor-to-category mappings that update deterministically, not probabilistic retrieval. We tried the RAG approach early on - it hallucinates categories at scale. The data layer we built is more like a traditional database with LLM-powered onboarding, not a vector search.