
Inferoa
Inference-native Tokenmaxxing Agent Harness built for Loop
10 followers
Inference-native Tokenmaxxing Agent Harness built for Loop
10 followers
Inferoa is an inference-native tokenmaxxing agent harness for Loop Engineering. Prompt engineering improves the next answer. Loop Engineering designs the system that keeps working after that answer: goals, feedback, memory, tools, verification, recovery, and proof. Inferoa makes that loop inference-aware. It keeps context, prefix cache, routing, model serving, and token spend visible while long-horizon coding work runs.



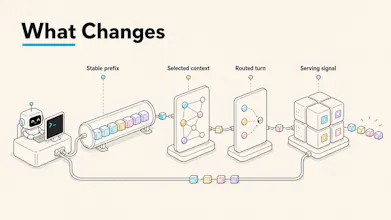




Introducing Inferoa, an Inference-native Tokenmaxxing Agent Harness for Loop Engineering.
Prompt engineering improves the next answer. Loop Engineering designs what happens after that answer: how the agent keeps the goal stable, reads feedback, uses tools, preserves memory, verifies progress, recovers from failures, and knows when the work is actually proven.
That is the problem Inferoa is built around.
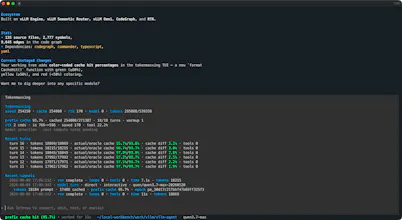
Long-horizon coding agents are not one prompt. They are recursive loops: inspect, edit, test, reflect, compress, recover, route, and continue. As the loop grows, inference stops being an invisible backend. Context fills up. Prefix cache breaks. Tool output gets noisy. Model routes become expensive. Serving constraints start shaping the result.
Inferoa makes those surfaces part of the harness itself.
Inferoa = Infer(Inference-native)o(Tokenmaxxing Loop)a(Agent Harness).
It brings together:
Goal/rubric driven work so long-running objectives can move across horizons with reflection, recovery, and completion evidence.
Feedback surfaces from plans, tests, tools, autoresearch metrics, and verifier-ready evidence, so the loop improves against something concrete.
Memory and context control through compression, summaries, graph-shaped code context, bounded history, and bounded tool output.
Prefix-cache discipline so durable sessions stay cache-friendly instead of drifting every turn.
Visible serving and routing so model paths can respond to cost, safety, privacy, capability, session pressure, multimodal needs, and whether a self-hosted vLLM path is enough.
Inferoa starts with coding because coding exposes loop pressure clearly: changing goals, tool failures, repeated model calls, context limits, verifier signals, and proof through tests.
The goal is simple: make long-horizon agent work more inspectable, more controllable, and more inference-aware.
Built around the vLLM ecosystem, with vLLM Engine, vLLM Omni, vLLM Semantic Router, CodeGraph, RTK, and a harness designed to keep the whole loop visible.
Try it:
npm install -g inferoa