
Google Gemma 4 12B
Run multimodal AI locally with an encoder-free architecture
513 followers
Run multimodal AI locally with an encoder-free architecture
513 followers
Gemma 4 12B processes text, vision, and audio natively without separate encoders, running on 16GB VRAM. For developers building local agentic applications who need multimodal capability without cloud dependency.

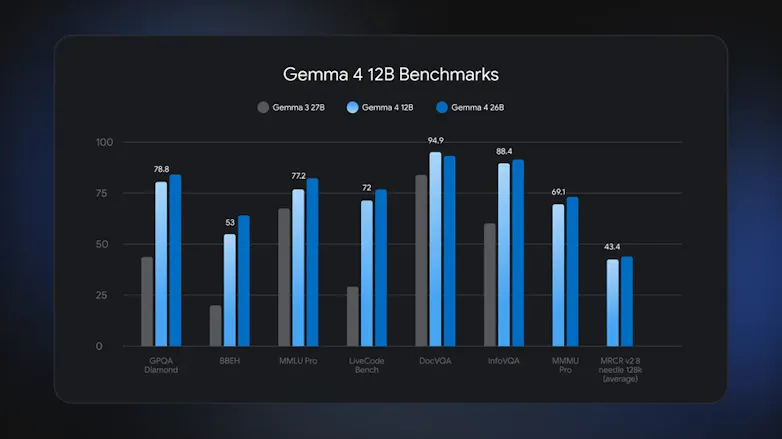


Gemma 4 12B is Google DeepMind's latest open-source model that processes text, images, and audio natively on consumer hardware, running on just 16GB of VRAM.
Most multimodal models carry a hidden memory tax: separate encoder stacks for vision and audio that inflate overhead before a single token is generated. Gemma 4 12B removes the encoders entirely. Vision runs through a lightweight embedding module, audio is projected as raw signal directly into the token space, and the LLM backbone handles the rest.
The result is a model that benchmarks close to Google's larger 26B MoE variant while fitting comfortably on a consumer laptop.
Key capabilities include:
🧠 Encoder-free architecture for native text, vision, and audio processing
💻 Runs locally on 16GB VRAM or unified memory
🤖 Reasoning performance nearing the 26B MoE Gemma model
⚡ Multi-Token Prediction drafters for reduced local inference latency
📦 Apache 2.0 license, available now on Hugging Face and Kaggle
🛠️ Compatible with Ollama, LM Studio, llama.cpp, vLLM, and HF Transformers
It is built for ML engineers and AI developers building on-device or edge applications that need multimodal capability without a cloud API dependency. Download the weights on Hugging Face or Kaggle and start building today.
P.S. I hunt the latest and greatest launches in tech, SaaS and AI, follow to be notified → @rohanrecommends
Encoder-free multimodal architecture is a bold call. Folding visual understanding directly into the transformer avoids the latency of separate encoder forward passes and reduces memory significantly. We've been wrestling with the privacy tradeoffs of calling external APIs for customer data, so local inference changes that calculus entirely. How does this affect LoRA fine-tuning? Can you still do efficient adapter-based approaches across both modalities?
16GB VRAM for text, vision, and audio without separate encoders is a big deal for anyone building local AI tools. most multimodal setups eat half your memory just loading the encoder stack before you even start doing anything useful. curious how this compares to gemma 26B in real-world tasks though... benchmarks say "close" but close can mean very different things depending on what you're actually building with it
The 16GB requirement is probably the most interesting number here. It feels like we're getting closer to a point where indie developers can build genuinely useful multimodal products without depending on external APIs for every interaction. Excited to see what people build when privacy, offline access, and multimodal AI can coexist on consumer devices.
PixFit
I have been witing for something like this for quite a long time!