
Darkmoon
Autonomous penetration testing platform
95 followers
Autonomous penetration testing platform
95 followers
Most AI pentesting tools stop at the web layer. Darkmoon goes further. Built by professional pentesters, it combines 18 specialized AI agents and 80+ offensive security tools to assess Active Directory, Kubernetes, cloud infrastructure, APIs, CMSs, and networks. Self-hosted, open-source, MITRE-mapped, and designed to deliver evidence-backed findings, attack paths, and publication-ready reports.




























@mehdi_boutayeb Congrats on the launch! It’s refreshing to see a security platform that avoids the AI hype and tackles complex environments like Active Directory and Kubernetes under a GPLv3 license.
Quick question: Since the orchestrator delegates tasks rather than executing tools directly, how do you manage or mitigate potential LLM hallucinations when it parses complex command outputs from tools like NetExec or BloodHound?
@laraib Great question.
This is actually one of the main reasons we designed Darkmoon around MCP-gated tool execution rather than letting the LLM directly interact with the environment.
The orchestrator doesn't generate findings from imagination. It works from structured evidence produced by the tools themselves. Outputs from tools such as NetExec, BloodHound, Nuclei, WPScan, Kubescape, etc. are collected, normalized and passed back as context for reasoning.
A few mechanisms help reduce hallucinations:
The LLM cannot arbitrarily execute commands. All actions must go through controlled MCP workflows.
Findings are expected to be evidence-backed. Reports include commands, outputs and supporting artifacts whenever possible.
Multiple steps often corroborate the same observation before it is promoted into a finding or attack path.
Specialized agents work within narrower scopes (AD, Kubernetes, WordPress, GraphQL, etc.) instead of relying on a single general-purpose agent for everything.
Human validation remains part of the process. Our goal is to assist pentesters, not replace their judgment.
In practice, we treat the model as a reasoning layer sitting on top of offensive tooling, not as a source of truth. The source of truth remains the evidence collected from the target environment.
This is also why we're very careful not to market Darkmoon as "fully autonomous hacking". The value comes from orchestrating tools, methodologies and evidence in a coherent workflow while keeping the process auditable and reviewable.
@mehdi_boutayeb Spend my days on the defensive side and "web scanner with an LLM wrapper" describes about 90% of the AI pentest space. methodologies stored as auditable Markdown mapped to MITRE, model plans while a separate layer executes, GPLv3 with no telemetry. good architecture, nice work.
Mailwarm
What’s the setup like to run a full assessment, and can you plug in your own tools or internal scanners?
@thamibenjelloun Hello, The setup is intentionally lightweight. Darkmoon is Docker-based, so a typical installation is essentially:
Once configured, you simply provide a target and the orchestrator handles methodology selection, tool execution, evidence collection and reporting.
Regarding custom tooling: yes. Darkmoon was designed around an MCP-based architecture and tool orchestration layer rather than a fixed scanner pipeline. The platform already integrates 80+ tools (Nuclei, NetExec, BloodHound, Impacket, Kubescape, WPScan, SQLMap, etc.), but organizations can extend workflows, methodologies and toolchains to fit their own environments.
Using the install-dev workflow, you can also install additional tools directly into the dedicated toolbox container, register them in the MCP server's authorized tools list, and expose them to the orchestration layer. Teams can go further by creating their own methodologies, custom workflows and agent playbooks to adapt Darkmoon to internal processes, proprietary scanners or specialized assessment scenarios.
More details are available in the documentation:
https://docs.dark-moon.org/
The philosophy is simple: the AI reasons, MCP controls execution, and the tools remain the source of truth.
Strong launch. I like the split between model planning and a separate execution layer. For security work, the useful artifact is not only the report, it is the chain from target scope to authorized tool to command output to finding. Do you keep that run record exportable for client or audit review?
@blah_mad Yes, auditability was one of the design goals.
In the open-source edition, you can export a complete session record, including the LLM reasoning process, executed commands, raw tool outputs and the resulting findings. This makes it possible to review how a conclusion was reached rather than only seeing the final report.
In the Professional Edition, the same execution history is preserved and accessible through the session history interface. Teams can review commands, AI observations, raw outputs and generated findings for each assessment.
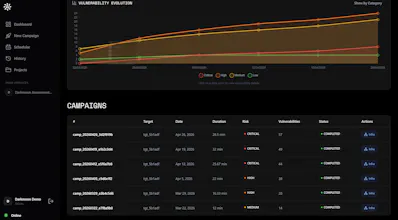
On top of that, the dashboard keeps a historical view of campaigns and vulnerabilities. Findings can be analyzed across projects, campaigns, severity levels and vulnerability categories. The platform also provides interactive trend visualizations, allowing teams to track whether vulnerability counts are increasing or decreasing over time and drill down into individual findings for investigation and remediation tracking.
Our goal is to make every finding traceable back to the evidence and execution path that produced it, rather than treating the LLM as a black box.
That is the right artifact. The open-source export is the useful bit for teams: not just “AI found X”, but target scope, command, raw output, and why it became a finding. Are those session records machine-readable enough to plug into a client’s ticketing or evidence workflow?
@blah_mad Yes, that’s exactly why we introduced a dedicated findings pipeline instead of relying solely on the final report generation step.
Each validated finding can be pushed through a dedicated MCP “push finding” function and stored as a structured JSON record.
These records contain the target context, reproducible commands, raw outputs, evidence, explanations, severity, attack-path context and remediation guidance.
The final Markdown report is then reconstructed from these structured findings rather than generated from the model’s memory of the assessment.
In practice, this makes the data much easier to consume programmatically and opens the door to integrations with ticketing, evidence-management and vulnerability-management workflows.
If you’d like to see the resulting artifact, you can explore the demo environment and review one of the generated Markdown reports:
https://demo.dark-moon.org
The report format is identical to what the Community Edition generates, while the Professional Edition builds additional dashboards, historical campaign views and vulnerability analytics on top of the same underlying evidence model.
That pipeline shape is the right split: structured evidence first, report second.
For the MCP push finding step, do you require a human validation point before it becomes ticket/evidence workflow input, or can validated findings flow out automatically once the assessment passes?
Congrats on Darkmoon! Autonomous pentesting is a huge pain point — most teams only test before major releases. How does Darkmoon handle false positive rates compared to traditional scanners like Burp Suite?
@dannyheng Thanks!
False positives were actually one of the main design challenges we wanted to address.
The key difference is that Darkmoon doesn't treat a signature match as a finding. Traditional scanners are excellent at surfacing potential issues, but they often leave the analyst with a large queue to manually validate.
Darkmoon takes a different approach:
Evidence-driven findings. The agents orchestrate real security tools and workflows, then attempt to validate impact using the collected evidence rather than reporting solely on pattern matches.
Confirmation before promotion. Before a finding is marked as confirmed, Darkmoon tries to challenge its own conclusion. Weak signals, reflected payloads, generic HTTP responses or other inconclusive indicators are downgraded and clearly identified as unconfirmed.
Proof attached to every finding. Reports include commands, raw outputs, request/response evidence, logs and execution traces so analysts can understand exactly why a finding was produced.
We also try to be realistic about the trade-off. Darkmoon is designed to maximize coverage, so we'd rather surface a suspicious lead as Unconfirmed than silently miss it. The goal is not "trust the AI", but rather "here is the evidence, here is the reasoning, and here is how the conclusion was reached."
In short, we're not trying to replace analyst validation, we're trying to dramatically reduce the amount of manual triage required to get there.