
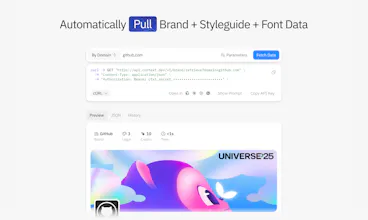
Context.dev gives your AI agents and apps real-time access to structured web data, no brittle scraping infrastructure needed. Scrape any URL as clean markdown or HTML, extract brand data (logos, colors, fonts, socials) from any domain, crawl sitemaps, resolve transaction descriptors, and more. Typed SDKs for TypeScript, Python, and Ruby. Trusted by 5,000+ businesses including Mintlify, Daily.dev, Ferndesk.com, and more. Most teams integrate in under 10 minutes.
This is the 2nd launch from Context.dev. View more
Context.dev
Launched this week
Context.dev is the web context API for AI products and agents. Scrape any URL, crawl sites, turn pages into LLM-ready Markdown, extract structured data into your own schema, capture screenshots, and retrieve logos, colors, fonts, styleguides, company data, and transaction enrichment through one API. YC-backed, no card required, and built so developers or coding agents can integrate in minutes.




Free Options
Launch Team / Built With




Migma AI
@yahia_bakour3 Congrats on the launch! We’ve been using your APIs for almost half a year now and they’ve been really reliable, fast, and delivering great results. Quality and speed are what matter most to us, and you’ve nailed both. Thank you, Yahia, for everything!
Context.dev
@liam007 Thank you Liam! It's been an absolute pleasure to know you guys, not many tech Syrian founders like us out there :)
Migma AI
@yahia_bakour3 ❤️❤️
the markdown output came back clean enough that i barely had to clean it up before feeding it into my agent. brand extraction on a few random sites was surprisingly on point too, definitely beats maintaining my own scrapers.
Context.dev
@sat966633299516 incredible to hear!
The "turn any page into LLM-ready Markdown" part is the piece I keep wishing existed — I do a lot of research-heavy work and getting clean, structured text out of messy pages is always the bottleneck before anything downstream is useful. Two genuine questions: how does it hold up on JS-heavy or auth-gated pages that don't render server-side, and is scraped content cached/versioned so I can tell whether I'm reading a fresh pull or a stale one? Typed SDKs across TS/Python/Ruby is a smart touch.
Context.dev
@hung_tran_from_notebook_os this reads a bit like AI but yes!
Really interesting approach Yahia. I'm curious—what was the hardest part to get right while building a single API that handles scraping, extraction, and enrichment reliably at scale?
Sounds great. How do you handle onclick events, if data is hidden and you have to click on an element to actually see it?
Context.dev
@thys_beesman My favorite thing about running this business is 90%+ of our customers are moving from an in-house solution or attempt at an in-house solution.
We're always the highest quality and most cost effective solution compared to the alternatives (including attempting to stitch in-house).
These fine people seem to agree: https://www.context.dev/customers