
Bench for Claude Code
Store, review, and share your Claude Code sessions
716 followers
Store, review, and share your Claude Code sessions
716 followers
Claude Code just opened a PR. But do you really know what it did? By using Bench you can automatically store every session and easily find out what happened. Spot issues at a glance, dig into every tool call and file change, and share the full context with others through a single link: no further context needed. When things go right, embed the history in your PRs. When things go wrong, send the link to a colleague to ask for help. Free, no limits. One prompt to set up on Mac and Linux.







Clipboard Canvas v2.0
I've tackled similar challenges with code reviews and context sharing, and I love how Bench automates session storage. How do you handle sensitive data in stored sessions to ensure developers aren’t accidentally sharing proprietary code?
Bench for Claude Code
@trydoff Hi there! :)
That really is a tough topic, that we will surely iterate on in the future. Right now, we moved in these directions:
you own your trace: you are free to delete any tracking code, along with all its related sessions, anytime you deem fit. You can even set expiration dates
we intentionally do not record any tool use OUTPUT, just the inputs, precisely because we want to do this right. And, when we'll implement this, it will become an opt-in feature for sure
you can define separate tracking codes for different uses: they are configured through simple envfiles, so it's quite trivial to keep data separated, and e.g. use a disposable tracking code for the activity logs that you may want to eventually delete in the future - or you may even just disable Bench altogether for specific projects if you need to
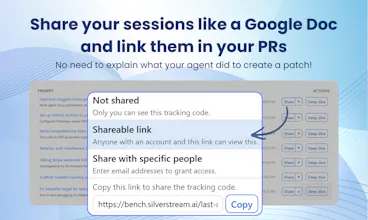
of course, the sharing functionality is opt-in and completely under your control, so you can share only the sessions that you deem right and stop sharing it whenever you want
It is also worth mentioning that our company, Silverstream, is part of our larger AI Alliance collaboration with CUBE (https://arxiv.org/abs/2603.15798) and we are in the process of offering an open source version, which will help to completely clear out that doubt if this concerns you too much.
I also encourage you to contact us at manuel@silverstream.ai to get further details about the whole process :)
Bench for Claude Code
Claude Code is so capable that we end up trusting it a little too much. But that's exactly when things get interesting:
I've had it silently migrate my local DB to an incompatible version while fixing a bug.
Another time, Claude decided the only way it had to fix an issue with a particulary inefficient for loop, was to turn off my audio drivers.
The real problem isn't that it made mistakes. It's that I had no way to go back and understand what it did, when, and why, to learn from it and finetune my prompts. Sure, I could just scroll the claude logs, but what if the "failures" weren't apparent until much later? Or what if the issue was at step 315 out of an hour-long agent run of 500 steps?
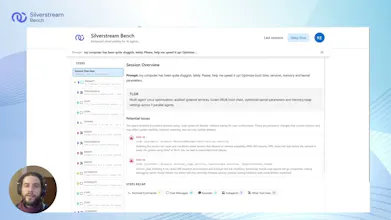
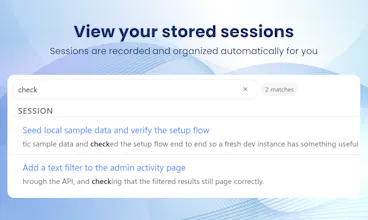
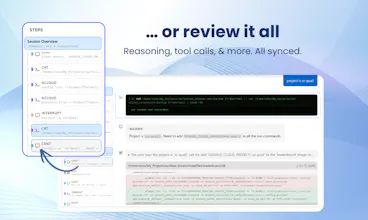
That's why Bench is a big deal. Not just a logger, but an audit trail that makes agent actions legible: every tool call, file change, conversation, subagent detail, all is there for you for as long as you need it, searchable and shareable. A great way to "share your context" to your colleagues, as well as being what I really needed to learn from my mistakes and improve in terms of prompt writing!
Now add observability + failure handling, otherwise it’s just scheduled guessing.
Bench for Claude Code
@ion_simion_bajinaru That's exactly what we are here for :) Providing observability for your sessions, both scheduled and in real time!
Unfold
heyy does this work only with claude? or i can use it with gemini, codex too?
Bench for Claude Code
@janhavidadhania Hey Janhavi! We are currently only supporting Claude Code. However, support for other agents is high priority in our feature list - so stay tuned! You can subscribe at bench.silverstream.ai to get notified when support for future agents will be available!
Bench for Claude Code
Hey folks! I’m Simone, Co-founder and CTO of Silverstream AI.
Really happy to be launching this today. I’m excited to share it, and very curious to hear your feedback!
One habit we’ve introduced across the team is linking Bench sessions in PRs whenever Claude Code was involved in creating or debugging a change. It gives reviewers a lot more context on how a bug was found and fixed, instead of just showing the final diff.
That’s been one of the most useful workflows for us, and I’d recommend it to other teams using Claude Code too.
I’m also using Bench in a research setting, where session data helps generate detailed methodology reports showing how results were obtained. I’m already finding it useful, and I think there’s a lot more to unlock there!
Looking forward to your thoughts. I want to make Bench as useful for other devs as it's been so far for us, and your input really matters!
OpenOwl
The session sharing feature is what makes this stand out. I've lost count of how many times I've wanted to show a teammate "hey look what Claude did here" and had to resort to copy-pasting terminal output into Slack.
Being able to just send a link to a full session with context would save so much back and forth. Especially useful for code reviews where you want to show the AI's reasoning, not just the final diff.
Bench for Claude Code
@mihir_kanzariya Exactly, that's one of the main reasons we created Bench! I hope we have effectively solved your issue. When you have the chance to try, please let me know how the experience was, and how we can improve the product!
Bench for Claude Code
Hey Product Hunt! I'm Omar, Founding Researcher at Silverstream AI.
We originally built Bench as an internal tool to make debugging our own agents less painful, and it's become something I reach for every day.
My favorite part? The high-level run overview. When an agent run has hundreds of steps, being able to scan the whole thing at a glance and immediately spot where something went wrong is a huge time-saver. From there, I can zoom in all the way down to the model's reasoning traces at the exact step where things broke, which makes a real difference when you're trying to understand why an agent made a certain decision, not just what it did.
As we kept adding features, we realized Bench had become too useful to keep to ourselves, so here we are! 🚀
We're starting with Claude Code, but support for more agents is on the way. Give it a try and let us know what you think!