
Alpie Core
A 4-bit reasoning model with frontier-level performance
211 followers
A 4-bit reasoning model with frontier-level performance
211 followers
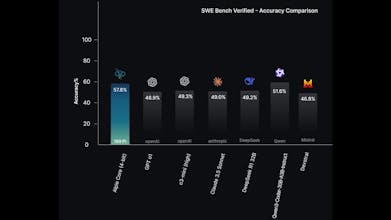
Alpie Core is a 32B reasoning model trained, fine-tuned, and served entirely at 4-bit precision. Built with a reasoning-first design, it delivers strong performance in multi-step reasoning and coding while using a fraction of the compute of full-precision models. Alpie Core is open source, OpenAI-compatible, supports long context, and is available via Hugging Face, Ollama, and a hosted API for real-world use.





Alpie Core
Hey builders
Modern AI keeps getting better, but only if you can afford massive GPUs and memory. We didn’t think that was sustainable or accessible for most builders, so we took a different path.
Alpie Core is a 32B reasoning model trained, fine-tuned, and served entirely at 4-bit precision. It delivers strong multi-step reasoning, coding, and analytical performance while dramatically reducing memory footprint and inference cost, without relying on brute-force scaling.
It supports 65K context, is open source (Apache 2.0), OpenAI-compatible, and runs efficiently on practical, lower-end GPUs. You can use it today via Hugging Face, Ollama, our hosted API, or the 169Pi Playground.
To keep you building over Christmas and the New Year, we’re offering 5 million free tokens on your first API usage, so you can test, benchmark, and ship without friction.
This launch brings the model, benchmarks, api access, and infrastructure together in one place, and we’d love feedback from builders, researchers, and infra teams. Questions, critiques, and comparisons are all welcome as we shape v2.
@chirag_a2207 This is a solid direction 4-bit end-to-end with 65K context is not easy to get right.
I run a security & adversarial testing practice focused on LLM / API / inference-time risks (prompt injection, jailbreaks, context poisoning, OpenAI-compat compatibility gaps, abuse vectors).
If you’re open to it, I'd be happy to do a free adversarial assessment of Alpie Core and share a short report with findings + mitigations.
No pitch just stress-testing before v2.
Alpie Core
@sujal_meghwal Really appreciate this, and thanks for the kind words. You’re absolutely right, getting 4-bit end-to-end with long context stability is non-trivial.
We’d be open to an adversarial assessment, especially ahead of v2. Stress-testing around prompt injection, jailbreaks, and inference-time risks is something we take seriously. Happy to connect and see how we can collaborate and learn from the findings.
Thanks for offering, will reach out to coordinate soon.
@chirag_a2207 Great. When you’re ready, I can share a short scope outlining what we’d test (prompt injection, jailbreak surfaces, long-context abuse, OpenAI-compat edge cases, inference-time abuse) and the format of the report so expectations are clear upfront. Happy to adapt it to whatever stage or constraints you’re working with. Looking forward to working with you and your team
What is the strenght of this compared to using api from openrouter? Do you think this is better to be used for putting into a product, or development?
Alpie Core
@peterz_shu Good question, Peter. OpenRouter is great for quick experimentation and model comparison. Alpie Core is designed to be a consistent, production-ready model that you can rely on for development and products, with predictable behaviour, lower latency, and improved cost control.
We’ll be available on OpenRouter soon for easy evaluation. For now, we’re offering a free first API key on our website so teams can test it properly and share feedback.
Alpie Core
@koderkashif Good question! Right now, it does need GPU VRAM or a fairly high-end CPU to run locally at this scale. That said, we’re actively optimising it further so it can run on more everyday laptops and eventually even phones over time.
Thank you for your interest. We will address this issue soon. Please stay connected for updates.
Congratulations on the launch! We are actually developing several AI startups based on ChatGPT. We’ll check out your product with our team; it might be applicable to our tasks.
Alpie Core
@mykyta_semenov_ Thank you, appreciate that. Do check it out with your team, as we’d be happy to jump on a call and share more context if helpful. It’s a state-of-the-art reasoning model at this scale, trained and served entirely at 4-bit, so it can be a good fit for real product workflows.
Looking forward to hearing your thoughts.