
Stigg
The Usage Runtime for AI Products
4.7•12 reviews•1.1K followers
The Usage Runtime for AI Products
4.7•12 reviews•1.1K followers
Stigg is the usage runtime for AI products: the real-time enforcement and governance layer between your app and your billing stack. It decides what every customer, user, team, and agent can do, the moment they try. Sub-millisecond credit checks, zero overdraft, enterprise governance, and modular BYOC. Metering, credits, entitlements, and governance in one runtime. Enforce in the request path instead of reconciling on the invoice. Free forever for AI startups.
This is the 2nd launch from Stigg. View more

Stigg 2.0
Launched this week
Stigg is the usage runtime for AI products: the real-time enforcement and governance layer between your app and your billing stack. It decides what every customer, user, team, and agent can do, the moment they try. Millisecond credit checks, zero overdraft, enterprise governance, and modular BYOC. Metering, credits, entitlements, and governance in one runtime. Enforce in the request path instead of reconciling on the invoice. Free forever for AI startups.






Free Options
Launch Team

Stigg
Hi everyone, Dor here, co-founder and CEO of Stigg.
Four years ago, Anton and I started Stigg because building pricing and entitlements in-house was quietly eating engineering teams alive. Every pricing change was a deployment. Every enterprise deal became a custom integration.
We were right about the problem. Then the AI wave made it much sharper.
The most sophisticated AI companies started building their own billing and access-control infrastructure from scratch, because nothing on the market could decide in real time whether a request should proceed.
A frontier lab's head of financial engineering put it simply: what they needed was something close to real time that could answer one question - do you have credits or not?
When a single API call costs real money and agents spawn sub-agents in milliseconds, "we'll reconcile at month-end" stops being a strategy.
Stigg 2.0 is our answer: the usage runtime for AI products. It decides what every customer, user, team, and agent is allowed to do, the moment they try. Credits, metering, entitlements, and governance in one system that sits alongside the billing stack you already have.
It's free forever for AI startups, because we want you building your product, not rebuilding ours. When you land the enterprise deal that breaks your homegrown system, we'll already be there.
We're launching at the AI World Fair. We'd love your honest take, try it, push on it, and tell us what's missing.
The sync-check, async-settle split is the right shape. The part I'd poke at is concurrent agent bursts: if an agent fans out 50 calls in one tick, they can all clear the credit check before the first debit settles, so how does zero-overdraft actually hold, do you place a hold or reservation at check time, or reconcile optimistically? We've had agent loops blow past a budget in exactly that window.
Grass
@dipankar_sarkar I second this
Stigg
@dipankar_sarkar You're describing the classic check-then-act race, and you're right that naive implementations break here. We support both modes, and the right choice depends on the use case: For strict budget enforcement, you can place a hold at check time. The estimated cost of the request is reserved against the balance atomically, so the 50 concurrent calls each see a decremented balance. When the actual usage comes in, the reservation is adjusted to the real cost. For latency-sensitive workloads where a small overshoot is acceptable, you can skip the reservation and reconcile async. You set an overdraft threshold (X% over the budget), and the actions are blocked once the settled balance crosses that threshold. This is what most AI-native teams prefer because they prioritize user experience over blocking users mid-action.
Embedding usage enforcement at the runtime layer rather than purely at the API gateway is the right call. Usage metering for AI products is uniquely hard because costs are nondeterministic and you need real-time enforcement without adding latency. How does Stigg handle the gap between estimated and actual token usage for streaming responses? That's where most quota systems get messy.
Stigg
@anand_thakkar1 Before a request starts, Stigg runs a lightweight entitlement check against a cached credit balance to decide whether to allow or block it. For streaming workloads, you can estimate the cost upfront based on input tokens plus a rough, model-specific estimate of output tokens - and since there isn't a deterministic way to predict output token usage, it's common to include a safety buffer in the estimate. Then you can deduct that amount from the balance before sending the request, and then reconcile it against the actual usage once the stream completes. The reconciliation happens through our event ingestion pipeline, which processes the final token count and adjusts the balance accordingly. If the actual usage exceeds the estimate, the difference is settled by deducting the remaining amount from the customer's balance.
Stigg
Hey PH, Anton here, Stigg's CTO with the under the hood bites behind Stigg 2.0!
When OpenAI published “Beyond Rate Limits” in February, they described a decision waterfall. Every request flows through a single evaluation path that synchronously checks rate limits, verifies credits, and returns one definitive decision, while debits settle asynchronously. Reading it, we recognized our own architecture. The hard part was never the idea. The hard part was making that decision correctly in single-digit milliseconds while an AI agent fans out into 50 parallel calls against a shared credit pool.
A few pieces I'm proud of:
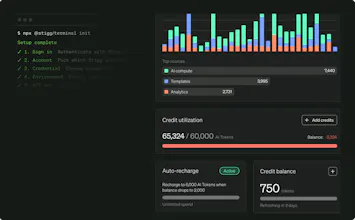
Credits run on a financial-grade ledger: balances update before the API response returns, overdrafts are enforced at the wallet level, and burn-down follows configurable priority rules: promotional first, expiring before non-expiring, paid last. An ASC 606-compliant ledger with full provenance.
Usage Governance enforces limits and user-level spend caps in under 5ms P99 on every request. This is the piece I think matters most. A power user burning through an enterprise’s entire allocation in a day isn’t something you fix on the invoice. You fix it at the point of consumption, or you don’t fix it at all.
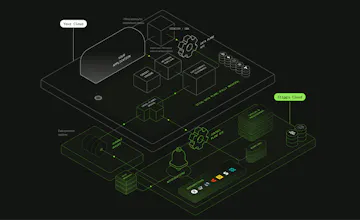
Deploy a complete metering stack in your own cloud: Kafka, Flink, and ClickHouse. Sustain 1M+ events per second with exactly-once guarantees where they actually matter.
Modular BYOC - Deploy every module independently into your own VPC. Metering, Usage Governance, and the Credits Engine run in your cloud, while configuration and management stay in ours. Clean trust boundaries, your topology.
Come break the demos, read the docs at docs.stigg.io, and tell me where it falls over.
That’s exactly the kind of feedback we’re looking for.
The configurable burn-down — promo first, expiring before non-expiring, paid last — is great on paper. I'm curious how it survives concurrency.
When 50 parallel debits hit the same wallet in one tick, keeping that priority order deterministic usually means serializing the debits… which fights your sub-ms goal.
Are you ordering these strictly, or is it eventually-consistent priority where a few paid credits might get burned before some promo ones under load?
the modular BYOC split is interesting - usage governance running in my own VPC while the credits engine stays centralized. what happens during a network partition between the two, where my enforcement layer can't reach the central ledger for a stretch. does governance keep enforcing against its last known balance, or does that gap turn into the same fail-open risk people are asking about elsewhere in this thread
Makes sense, the atomic hold is the answer I was hoping for. The bit I'd still watch is estimate drift: if you reserve worst-case output tokens per call, a 50-wide agent fan-out holds far more than it spends and can start false-blocking once the wallet is mostly reserved rather than actually spent. And a hold from a call that dies mid-stream leaks until something reaps it. Do you release the estimate-minus-actual delta on settle, and is there a TTL on orphaned holds?