
Hive
Babysits your agents from idea to PR, letting you think
35 followers
Babysits your agents from idea to PR, letting you think
35 followers
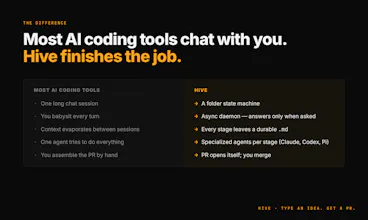
Hive orchestrates work of SOTA coding agents (Claude/Codex/Pi), so they run autonomously and asynchronously from idea to PR, while you provide only the critical product decisions. Right in your terminal. So instead of watching 5 terminals, you can outsource agents babysitting to Hive and do something meaningful.








InnerSense
Hi Product Hunt — I'm Ivan, the maker of Hive.
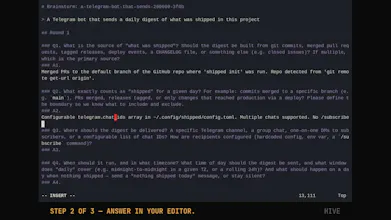
Hive is an open-source agent harness that drives SOTA coding agents (Claude, Codex, Pi) from a rough idea to a merge-ready PR. The mental model, borrowed from Kieran Klaassen's "the folder is the agent," is that every task is a directory: the folder's location is its state, and the .md files inside are the work. A daemon moves a task through 'brainstorm → plan → code → multi-agent review → PR', and you only step in when an agent actually needs you — usually just answering the brainstorm questions in your own editor (vim, in my case).
I've been dogfooding it hard. Hive's own codebase — now 55k+ lines of Ruby, not counting tests — was mostly written by Hive itself (about 70% when I last measured), and the demo above is a real run on a fresh project that ended in this merged PR: https://github.com/ivankuznetsov....
The recently shipped Hive v0.2.0 added a repo patrol that opens PRs on its own, a babysitter daemon that keeps open PRs rebased and green, and Telegram idea capture with voice notes.
You don't even have to leave your agent: Hive ships an OpenClaw skill (`openclaw skills install hive-cli` gives you a `/hive` command with guided setup), and you can drive it from inside the Hermes agent the same way.
Honest caveats up front:
- Hive is token-heavy by default (many subagents + multiple coding agents). It's free and open source, but to really try it I'd recommend a Claude Max + ChatGPT Pro (Codex) subscription — that's where it shines.
- Claude's tmux mode (the default — it bills against your Claude subscription instead of API credits) is the newest part of the stack — expect some rough edges.
- I'm a solo dev building this in spare time, so testing across OSes and workflows is thin. Feedback and issues are very welcome.
- Prefer a browser? Hivebox — a dockerized Hive with a web UI — is the next release, about a two weeks out. The Discord hears about it first.
Full write-up with the same demo: https://ikuznetsov.com/posts/int...
Discord: https://discord.gg/Qg5E7rMt
Repo: https://github.com/ivankuznetsov...
Happy to answer anything in the thread today
Interesting positioning. A lot of developers are comfortable delegating coding tasks to agents, but not necessarily the coordination layer around them.
How do you handle conflicting outputs from multiple agents? Is Hive choosing the "best" solution automatically, or does it surface tradeoffs for the developer to decide?
InnerSense
@farrukh_butt1 triage with Claude. First of all agents don't talk to each other, they write documents one after another, and they Claude triage the findings.
Humalike
Clean launch! How are you measuring whether it is working for people?
InnerSense
@mcarmonas Very good question. Now mostly vibe-based evaluation based on my project. That's why I'm here, I need a feedback from real users. I dogfood it hard, with a lot of different cases.
Also I'm pretty limited in evaluation methods -- it's an opensource tool that works on your machine, I haven't added any remote telemetry for it, but I have some plans to do it with opt-in model (but honestly I don't think many people will send even anonymized telemetry to me).
As a more broad vision I work on the hive-bench, benchmark based on a real tasks. I will add an option to send your real task to the open online benchmark (anonymized, stripped of secrets etc). So with some of the participation of the community I will be able to create diverse benchmark on real tasks from different people, completely open and reproducible. I now do it on my own tasks to explore how good different coding agents and models will work, like should I use Opus 4.8 here or Kimi k2.7 will be good enough. I think my next big iteration apart from the HiveBox will be evaluation of opensource models and harnesses on real workflows, because public benchmarks shows just granular tasks performance, and I have workflows which may show completely different results.