Launching today

scritty
Shared, searchable memory for every AI coding agent
72 followers
Shared, searchable memory for every AI coding agent
72 followers
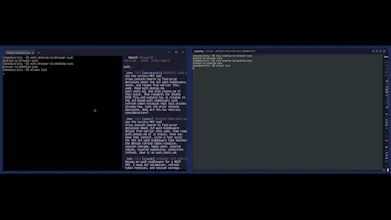
scritty is a terminal emulator that captures every CLI agent's conversation (Claude, Codex, Copilot, Antigravity, Ollama), indexes it into one searchable corpus you control, and serves it back to your agents over MCP and to you over the CLI. One session across desktop, browser, and mobile. Your captures stay on your machine.
Interactive







Free Options
Launch Team / Built With



scritty
The context loss between agents is real and nobody talks about it
enough. I've been using Claude Code heavily and the moment you hit
a usage limit mid-session the mental overhead of rebuilding context
somewhere else is brutal — you spend the first 10 messages just
catching the new agent up instead of actually solving the problem.
The MCP angle is the part that makes this different from just
"searchable logs." Agents querying each other's past turns rather
than starting cold is a genuinely different model. Curious how the
retrieval quality holds up on longer sessions — does it surface
the right past context or do you find yourself still needing to
manually point it at the right conversation?
Also the prompt.toml injection is underrated. Maintaining consistent
rules and persona across agent switches without copy-pasting is
something I'd use daily.
The case I would test hard is stale or wrong memory, not just recall. If one agent records a bad debugging hypothesis and another agent asks about the same repo tomorrow, can I mark that capture as superseded or incorrect so it stops being retrieved?
For coding agents, I would want each memory hit to show source session, repo/branch, timestamp, and whether it was later contradicted. Local storage is a good default, but stale local facts can still send the next agent down the wrong path.
how does it actually capture the conversation from agents like Codex and Copilot, do you have to wrap the calls or does it hook into the terminal session itself?
The context loss when you switch from Claude Code to another agent mid problem is exactly what kills me, so pulling it all into one searchable memory over MCP is a great idea. Does it keep the full transcript searchable or summarize once a session gets big? Congrats on shipping.
the piece i keep waiting for. every agent has its own memory silo which means every session gets rebuilt from scratch. cross-tool memory should be a standard everyone shares. also the fact that it stays local instead of getting phoned home makes this ok to leave running.
question for v2: does the index know when two conversations are about the same thing but happened in different tools, or is it just full text search? that dedupe is where this gets scary useful.
If I'm working across multiple client projects that shouldn't ever mix, is the corpus scoped per project/repo by default, or is it one global memory that I'd have to manually wall off? Worried about an agent on project A accidentally surfacing something it learned while I was working on project B.