
Hyperion
LLM API gateway, microsecond latency, 250× faster vs LiteLLM
1 follower
LLM API gateway, microsecond latency, 250× faster vs LiteLLM
1 follower
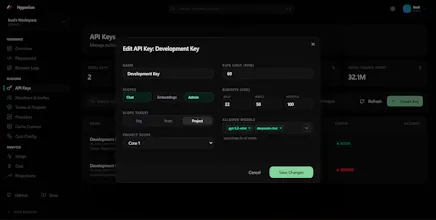
Hyperion is a high-performance LLM gateway with ~5µs overhead (~250× lower than LiteLLM). It handles smart routing, semantic + exact-match caching, rate limiting, budget control, PII redaction, and failover through a single OpenAI-compatible API. Built in Go with Redis, Qdrant, and ClickHouse.







Free
Launch Team / Built With


Hey everyone, Hyperion team here.
We built Hyperion after repeatedly running into the same problem: routing, caching, retries, and cost control all living inside application code.
Hyperion pulls that into a single gateway with ~5µs overhead (~250× lower than LiteLLM), so it can sit in the request path without slowing things down.
It includes smart routing, semantic + exact-match caching, rate limiting, budget enforcement, PII redaction, failover, and real-time analytics.
Would love feedback from anyone working on similar LLM infra